Blog
はじめまして、新入社員の阿部です。入社して3ヶ月経ちました。
この記事では、歩行者検出の手法である Integral Channel Features について解説したいと思います。
はじめに
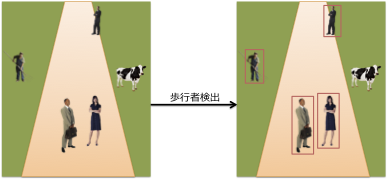
歩行者検出(人検出)は画像認識のメジャーな問題のひとつで、読んで字の如く画像中の歩行者を見つけるという問題です(上図)。たくさんの応用が考えられるため盛んに研究されていましたが、特に「顔検出」の実用化のメドがたった2000年代はじめから顔検出の次の問題として研究が活発になったようです。
人検出の手法の基本的なアイデアは顔検出のものと共通ですが、人検出に特有の難しさとして大きな姿勢変化や隠れが起こりやすいこと、髪型や服装、体型等に多様性があり、これらを克服するための様々な方法が研究されています。本記事では高精度かつ高速な検出手法として近頃注目されている”Integral Channel Features”について解説します。人検出手法の分野全体の最新動向に興味がある場合は、山内さんらによる日本語のサーベイ、Dollarらによるサーベイ・ベンチマーク(Pedestrian Detection: An Evaluation of the State of the Art)をおすすめします。
今回解説するIntegral Channel Featuresは2009年のBMVCで発表されました。
[1] P. Dollár, Z. Tu, P. Perona, and S. Belongie. Integral channel features. In BMVC, 2009.
http://www.loni.ucla.edu/~ztu/publication/dollarBMVC09ChnFtrs_0.pdf
その基本的なアイデアは、顔検出のエポックメイキングな手法として有名な(OpenCVにも実装されている)Viola-Jonesの顔認識手法[2]を拡張したものです。Viola-Jonesの顔認識手法(VJ)はとてもメジャーなので方々で日本語の解説がなされていますが、この記事でも簡単に説明します。詳しい解説として中部大学藤吉先生による資料等があります。
Viola-Jonesの手法
VJは大きく以下の要素で構成されています。
- Haar-like特徴
- AdaBoostによる特徴選択と学習
- カスケード型分類器による高速化

Haar-like特徴
Haar-like特徴は正と負の矩形領域の特定パターンでの組み合わせからなります(上図)。このような矩形パターンを画像の様々な場所に適用して得られる特徴量は、正領域内の輝度値合計から負領域内の輝度値合計を引いた値として計算されます(上図)。たとえば上図のように−+−型のHaar-like特徴が眉間のあたりに適用された場合には、出力される特徴量の値は眉間周辺の領域(緑)の輝度値合計から両目周辺領域(赤)の輝度値合計を引いた値
\(\sum_{(x, y) \in P}{I(x, y)} – \sum_{(x, y) \in N}{I(x, y)} \)
となります。
こうした特徴量は、たとえば目や唇がそれらの周辺領域に比べて輝度が小さいといった、顔を認識するための手がかりを捉えることが出来ます。ただし、このような単純な計算で得られる特徴量は、ひとつひとつが強い識別能力を持っているわけではありません。このような単純な特徴をたくさん組み合わせることにより顔のような複雑な形状を認識するというのがVJの基本的なアイデアです。
積分画像
Haar-like特徴の計算はナイーブに行えば矩形領域の面積と同じ回数の加算が必要ですが、これは積分画像というテクニックを使うことで大幅に高速化することができます。
積分画像は各画素\((x, y)\)の画素値を元画像の矩形領域\((0, 0)\)-\((x, y)\)の画素値合計とした画像、つまり積分画像Sの\((x, y)\)の値は
\(S(x, y) = \sum_{v=0}^{y}{\sum_{u=0}^{x}{I(u, v)}}\)
です。
積分画像を事前に計算しておくことで、任意の矩形領域内の画素値合計をたった数回の加減算で求めることが出来ます。たとえば、矩形\((x_1, y_1)\)-\((x_2, y_2)\)内の合計は、
\(S(x_2, y_2) – S(x_1-1, y_2) – S(x_2, y_1-1) + S(x_1-1, y_1-1)\)
と計算することが出来ます(下図)。

AdaBoostによる特徴選択と学習
膨大な数のHaar-like特徴の候補(どのパターンをどこにどういうスケールで適用するか)が識別に有効であるか、それらをどう組み合わせて認識するかを学習によって決めるために(弱識別器として決定株を用いる)AdaBoostが使われます。
学習に使われるデータは正例(顔画像)と負例(顔ではない画像)を多数集めたものです。AdaBoostは学習データを正しく分類できるHaar-like特徴を反復的に、Greedyに選択します。反復の過程でサンプルに重み付けを行い、これまで選択した特徴で正しく分類できていないサンプルをうまく分類できる特徴が選択されるようになっています。これにより無数のHaar-like特徴の候補から、認識に有効な特徴だけを選択して組み合わせて分類に使うことが出来ます。AdaBoostの詳しいアルゴリズムについてはWikipediaの記事等のわかりやすい資料が公開されています。
カスケード型分類器
大きな画像から物体を検出する場合には、画像から部分領域を切り出しそれに対して顔か否かの二値分類を行います。そのため一枚の画像から検出を行うだけでも莫大な回数(解像度640×480の画像から2px間隔で切り出した場合7万以上)の分類を行う必要があります。
これを高速化するために積分画像に加えて、分類器をカスケード型に構築するという方法を使います。
カスケード型分類器は複数の分類器が一列につなげられたもので、分類の際には先頭の分類器から順番に適用しNegativeと分類された時点でそのサンプルを棄却し、全ての分類器がPositiveと分類したサンプルだけをPositiveとします。はじめのほうの分類器では比較的少数の特徴だけを使って明らかに顔ではないサンプルを棄却し、後半ではよりたくさんの特徴を使って複雑な分類を行うようにすることで、全体として特徴を計算する処理を大幅に削減することが出来ます。
Integral Channel Features
Integral Channel FeaturesはこのVJの手法を非常にシンプルに拡張したものです。
VJでは輝度だけを使って特徴を計算していましたが、この手法では入力画像(カラー画像)に対して線形・非線型の様々な変換処理をかけ、複数のチャンネルの画像を生成します。こうして作られた複数のチャンネルに対して、Haar-like特徴を単純にした(パターンを使わず単純な矩形領域の合計を見る)特徴を計算します。これは輝度だけを用いた場合に比べてリッチな特徴を得ることが可能で、さらに検出対象に応じた情報を捉える様々なチャンネルを加えることが容易なフレームワークになっています。たとえば、人検出には輝度勾配の方向を活用する手法(HoG[3])が一般的ですが、このフレームワークなら特定方向の勾配を計算したチャンネルを加えることでHoGと同等の特徴を組み込むことが出来ます。
学習と特徴選択についてはVJと同様にAdaBoostを使います。カスケード型分類器を用いることもほぼ同じですがより洗練された手法であるsoft cascade[4]を利用することが一般的です。
![入力画像の変換 [1]より](https://tech.preferred.jp/wp-content/uploads/2013/07/channels.png) ([1]より)
([1]より)
上図は入力画像の変換について説明したものです。考えられる画像変換の一例として、(a)入力カラー画像を輝度画像にする、(b)表色系を変換する、(c)ガボールフィルタをたたみ込んで特定方向の勾配画像を求める、(d)DoGフィルタをたたみこむ、(e)勾配強度を求める、(f)エッジ検出する、(g)直線のフィルタをたたみ込んで特定方向の勾配画像を求める(ガボールフィルタとほとんど同じ)、(h)閾値処理で二値化するなどが考えられます。この他にも入力画像を同サイズの画像へマップする変換であればどのようなものでも使うことが出来ます。
特徴量はこうして作られた様々なチャンネルのうちひとつの、ある矩形領域内の合計値によって計算されます。Haar-like特徴は正の領域と負の領域が特定のパターンで組み合わされたものでしたがここではそうしたパターンは使われず正の領域だけからなる矩形領域内の合計を使います。論文中では正負の矩形領域を組み合わせて差を使う方法も検討されていますが、性能の向上は特に見られず単純な単一の矩形で十分なことが示されています。こうした矩形内の合計値はVJのときと同様に積分画像を使うことで高速に計算することが出来ます。
どのチャンネルのどの領域を見るかでとりうる特徴の数は膨大ですが、VJと同様にAdaBoostを使ってこれらのうち有効な特徴を選択して組み合わせて分類を行います。学習のプロセスはほとんど同じで、違いは単純なカスケード型の分類器ではなくより洗練された手法であるsoft cascadeを利用することだけです。
実験的に人認識には勾配方向(ガボールフィルタか直線のフィルタをかけた画像)と勾配強度、LUV表色系の各チャンネル、勾配方向を6方向に量子化した場合には合計10チャンネルを使うのが良いようです。下図は画像を各チャンネルに変換した結果と、AdaBoostにより選択された特徴がどのチャンネルのどの領域をみるものが多かったかを示すヒートマップです。これをみると肩周辺のエッジや、顔の肌色に反応する特徴が選択されていることがわかります。
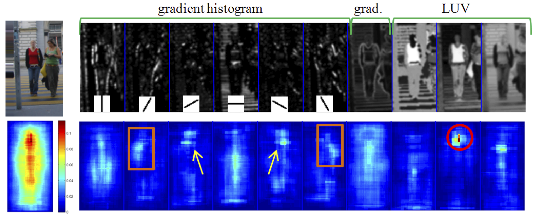 ([1]より)
([1]より)
この論文中では640×480の画像から異なるスケールの人を認識するのにおよそ2秒の計算時間が必要だとされていますが、現在では、これを高速化するための手法[5]が提案されておりGPU上での実装を用いた場合にはリアルタイムでの検出が可能になっています。さらにステレオカメラを用いてシーンの幾何情報を取得し人が存在しうる領域を限定して検出対象範囲を小さくすることで100fpsを達成したという研究もあります[6]( 動画 )。
まとめ
人検出手法の中でも高速かつ単純で実装も複雑にならず、チャンネルの選び方次第で様々な物体に適用できうるIntegral Channel Featuresは非常に有望な手法であると個人的には考えています。
最後に、最近社内で開発している画像認識のためのライブラリによる人検出結果(Integral Channel Featuresを使用)をお見せして終わりにしたいと思います。ありがとうございました。
次は背景差分法で動画から移動物体を検出する処理について書きます。よろしくお願いします。

[2] P. Viola and M. Jones. Robust real-time object detection. IJCV, 57(2):137–154, 2004.
[3] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In CVPR, 2005.
[4] C. Zhang and P. Viola. Multiple-instance pruning for learning efficient cascade detectors. In NIPS, 2007.
[5] P. Dollár, S. Belongie, and P. Perona. The fastest pedestrian detector in the west. In BMVC, 2010.
[6] R. Benenson, M. Mathias, R. Timofte, and L. Van Gool. Pedestrian detection at 100 frames per second. In CVPR, 2012.
Tag