Blog
得居です。3月下旬とは思えない寒さに凍えています。
Facebook が CVPR2014 に投稿しアクセプトされていた顔認証に関する論文 [1] が MIT Technology Review にて紹介されたことで注目を集めています。DeepFace と名付けられた手法で、同社が集めた4030人の顔写真440万枚を用いた大規模学習によってほぼ人間並の人物識別性能を達成しているということで、なかなかキャッチーな話題です。一方、Face++ という顔認証・分類のプラットフォームを展開する Megvii社 がつい先日公開したプレプリント [2] でも DeepFace と同程度の性能を達成しています。今日はこの2つの論文を解説します。
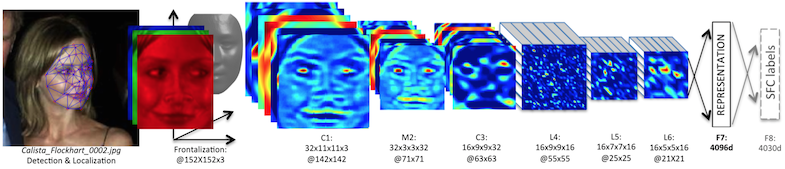
DeepFace の論文では、検出された顔矩形に対して以下の3つの処理を施しています。
- 矩形の2次元アラインメント
- 3次元モデルを用いた out-of-plane のアラインメント
- アラインメントされた画像を Deep Neural Network (DNN) に入力して顔表現ベクトルを得る
- 得られた顔表現ベクトルをもとに2つの顔矩形を比べて、同一人物化どうかを判定する
前半のアラインメント部分は深層学習とは関係ありませんが門外漢として興味深いです。2次元アラインメントでは顔のうち特定の6箇所(両目、鼻の先端、両口角および下唇の中心)を検出し、その位置が合うように画像の位置とスケールを調整します。特徴点検出には Local Binary Pattern と呼ばれる特徴を用いた Support Vector Regression を用いています。3次元アラインメントではさらにこの特徴点を67点に増やし、予め用意した標準的な顔の3Dモデル(顔3Dモデルのデータセットに対して平均をとったもの)の対応する基準点に対応させて特徴点の3次元位置を推定します。これをもとに、3次元空間の点をカメラの平面上に射影するカメラ行列を推定します。正面から撮った場合の特徴点の位置を求めます。同時に、特徴点を頂点とするポリゴンを生成しておき、元画像の画素値を正面画像の対応する三角形上にアファイン変換します。こうして斜めを向いた画像からも正面顔画像が得られます。顔の一部が隠れている場合、見えている側の画像で補完するような処理も行っているようです。
DeepFace で用いる DNN は一般的な画像認識で用いられるものとは少し変わっています。画像認識では位置不変な特徴を捉えるために畳み込み層とプーリング層を用いるのが一般的です。一方 DeepFace の場合は入力画像がアラインメントされているので、位置不変性がそこまで必要になりません。低次の特徴(エッジやテクスチャ、グラデーションなど)は位置不変の特徴で十分ですが、高次の特徴(目、鼻、口やより広い範囲の顔部分)についてはむしろ位置ごとに異なる特徴を捉えたくなります。そこで DeepFace では3層目以降で位置ごとに異なる重みを用います。また、1層目以外ではプーリング処理も行いません。畳み込み・プーリングを用いた場合との比較がされておらず、個人的には効果のほどに懐疑的ですが、工夫としては面白いと思いました。
さて、この DNN の学習ではまずデータセット内のどの人かを判別する 4030 クラス分類問題を解きます。得られたネットワークの最後の隠れ層を顔の表現ベクトルとして実際の顔認証に用います(ここは距離ベースの手法を使っていて、その部分でも Neural Net を使う方法も試しています)。DeepFace の難しい点は、平行移動による data augmentation が使えないことです。画像認識ではよく、入力画像を少しずらしたものも訓練データに加えることでデータを水増しすることをよくします。これを data augmentation と呼びますが、複雑な DNN を学習するため非常に有用な方法です。ところが DeepFace の場合、入力のアラインメントに依存したモデルを学習するのが目標なので、ずらした画像を使うわけにはいきません。440 万枚という大規模データセットを作ったのにはここらへんも理由だったりするのかなと想像しています。
結果はみなさんすでにご存知かと思いますが、人間に肉薄するレベルとされています。Labeled Faces in the Wild (LFW) データセットにおいて 97.25% の正解率で、これは検出された人画像矩形だけを見たときの人間の回答 97.53% にかなり近いレベルです。間違った画像には、年をとるなどして見た目が大きく変わった人物の同定などが含まれていて、人間にも判別が難しいということです。
さて、一方で冒頭で紹介した Face++ の論文も紹介しましょう。こちらはより標準的な方法で、Convolutional Neural Network (CNN) を用いています。ただし、学習の仕方が少し変わっています。ネットワークは shared layers と unshared layers に分かれていて、shared layers が入力側に並ぶような形になっています。まず1層だけの shared layer を用いて、顔画像のうち小さなパッチを入力として学習を行います。得られた重みのうち shared layer の部分だけを残して、一段 shared layer を増やしてもう少し大きなパッチで学習します。これを繰り返して、最終的に深い CNN を学習します。これは一種の greedy layerwise training ですが、教師ありで行う点、毎回出力側に余計なレイヤーを挟む点が特殊です。この方法を著者らは Pyramid CNN と呼んでいます。はじめの方では小さなパッチを入力として学習しますが、その際には後ろの unshared layer をパッチの位置(目、鼻、口など)によって異なるものを使う方法も提案していて、学習コストは上がりますが精度が上がることを確認しています。Pyramid CNN は、顔の色んなパーツやスケールにおける特徴を識別の観点から学習することに主眼を置いていると言えます。
Pyramid CNN の学習では外部のデータセットは用いずに LFW のデータセットのみで学習・評価を行っています(標準的な方法です)。正解率の結果は出ていませんが、DeepFace 論文と比較可能なROC曲線が載っていて、単体の CNN としてはほぼ同程度の性能を達成しているように見えます。こちらも人間並の精度と言うことができそうです。面白いのはこちらでは比較的小さなデータセット(1万枚程度)でも近い性能を発揮している点です(ただし同じデータセットで学習・評価を行っている点には注意)。細かい実験プロトコルが載っていないのでわからない点もありますが、DeepFace と比較するとパラメータ数が少ないので小さなデータセットでもうまくいっているのかもしれません。個人的な印象としては DeepFace の方がさらに精度を伸ばす余地があるのかなと思っています。
以上、今話題の DeepFace に加え、Pyramid CNN を紹介しました。深層学習の実験や工夫の例として興味深い内容だと思いますので、論文本体も読んでみることをおすすめします。
[1] Y. Taigman, M. Yang, M.’A. Ranzato and L. Wolf. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. CVPR2014.
[2] H. Fan, Z, Cao, Y. Jiang, Q. Yin and C. Doudou. Learning Deep Face Representation. arXiv:1403.2802.



