Blog
新入社員の松元です。はじめまして。
“分散深層強化学習”の技術デモを作成し、公開いたしました。ロボットカーが0から動作を学習していきます!
まずはこの動画を御覧ください。
以下で、動画の見どころと、使っている技術を紹介します。
動画の見どころ
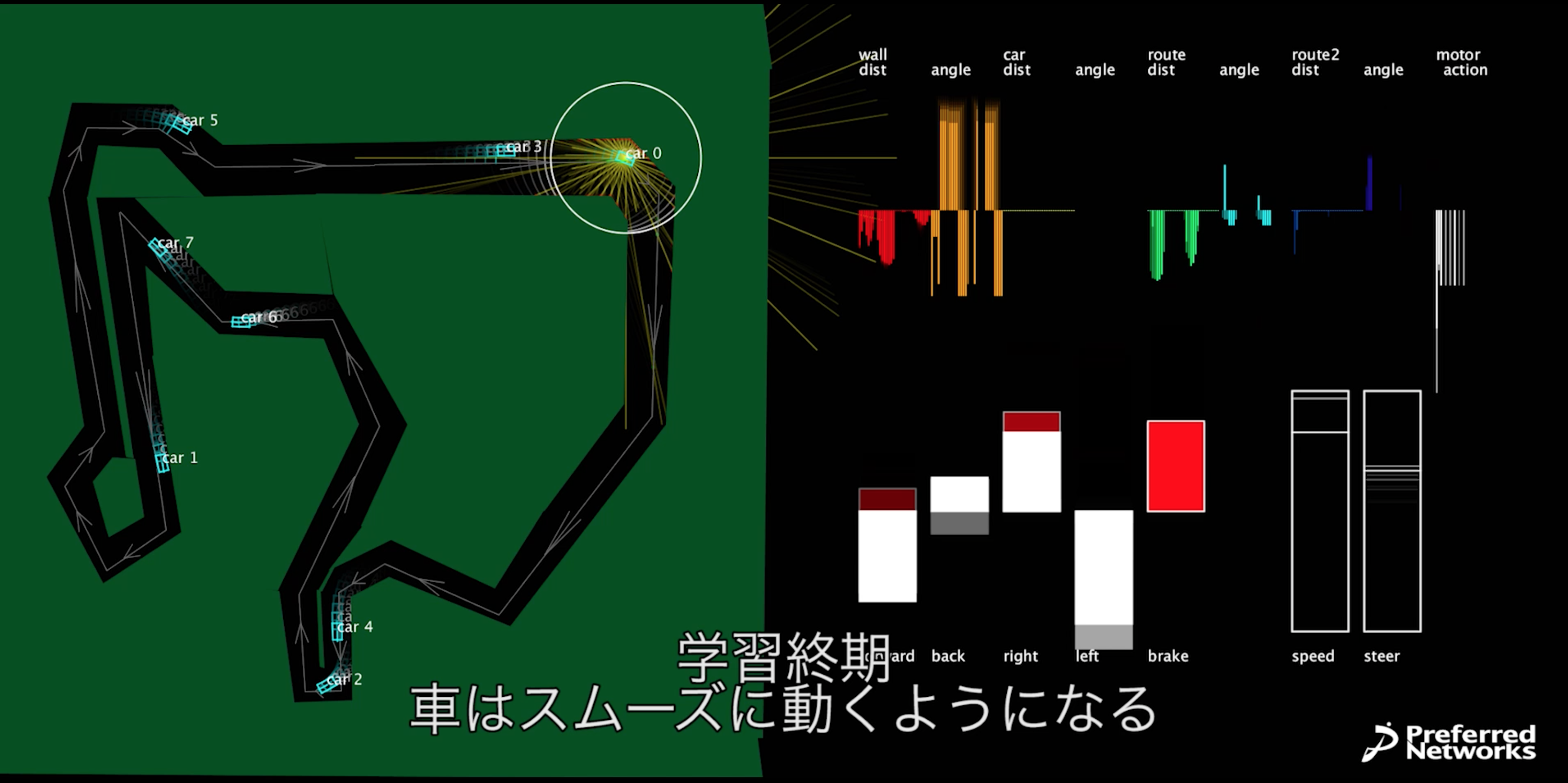
Car 0(○の付いている車)が右折カーブの手前で減速する様子(右画面の白いバーのところが、ブレーキのところで赤くなっている。ニューラルネットはブレーキが最も多く報酬が得られると推測していることがわかる)。速い速度ほど報酬は大きいが、カーブを曲がりきれず壁にぶつかってしまうので学習が進むとカーブ手前でのみ減速するようになる。
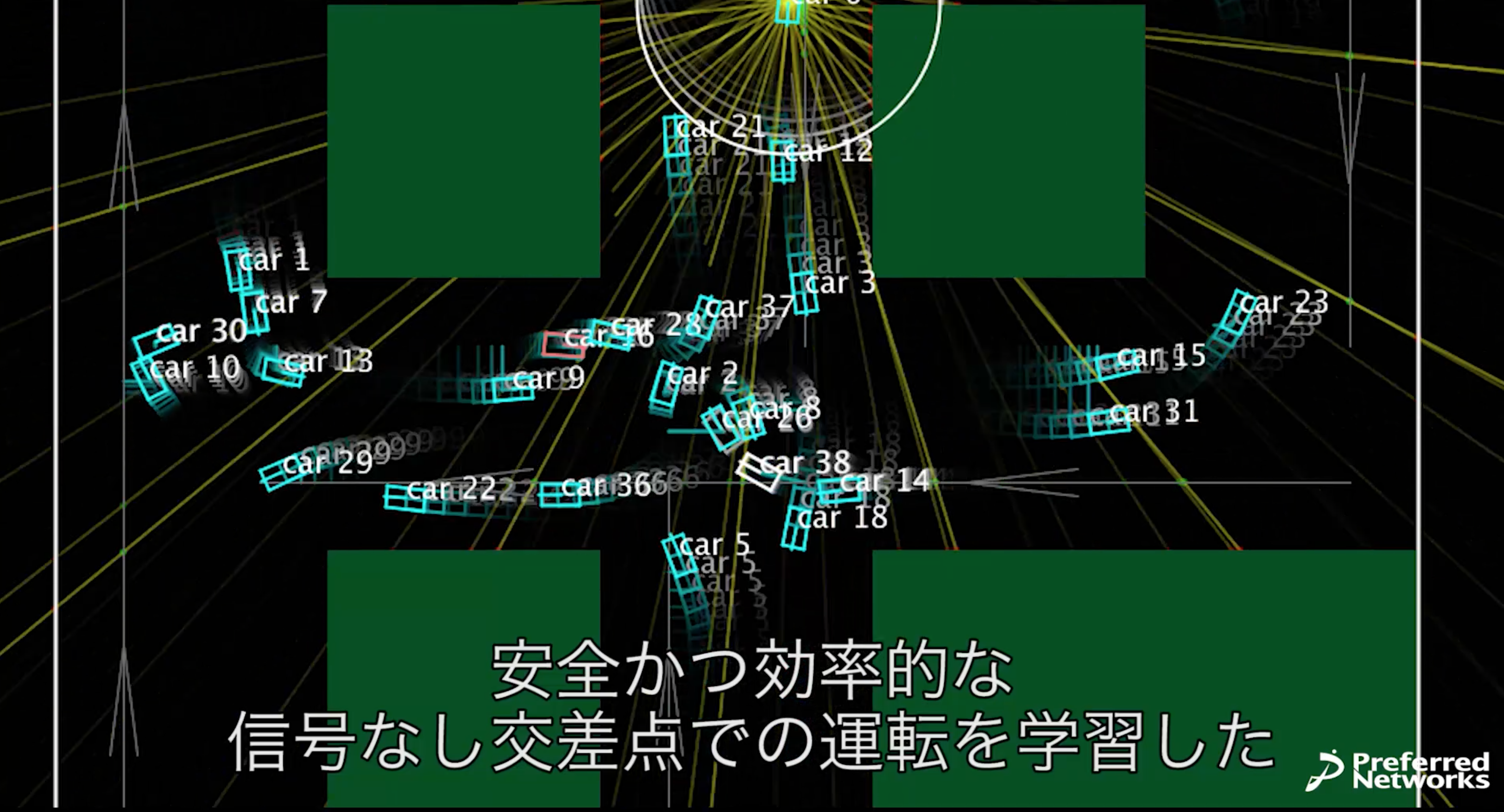
目の前に車がいるときは一時停止して、いなくなってから加速する。
エチオピアには本当にこのような交差点があるらしい。

ぎりぎりですれ違う2台。学習途中ではすれ違いきれずにぶつかって倒れてしまうこともある(早送りシーン中に人が写っているのは、倒れたり詰んだりするたびに起こしていたためです)。
この動画で使われている技術について少し解説をしたいと思います。
強化学習
このデモにおけるロボットは、強化学習という手法で学習しました。
よくあるロボットの制御では、ある状況でどの行動をとるべきかのルールを人間が作り、そのルールに従って制御を行ったり、ロボットの取るべき軌道を予め人間が設計しておいて、その目標とのズレが最小になるように制御を行います。しかし、あらゆるシチュエーションに対してとるべき行動を設計するのはとても大変です。それに、臨機応変に軌道を変更することができません。
そこで、強化学習では、目標とするロボットの最適な動きを正解として与える代わりに、ロボットの各行動に対して報酬を与えます。今回の課題では、道にそって速い速度で進んだときにプラスの報酬を、壁や他の車にぶつかったり、道を逆走したときにマイナスの報酬(罰)を与えています。
ロボットはどのように行動するとどれくらいの報酬が得られそうかを学習していき、最も多くの報酬が得られそうな行動を選択することで、結果的に最適な行動をとることができるという仕組みです。これによって、「障害物が何mの位置に来たら、ハンドルを何度に回す」みたいなルールを人間が設計しなくても、自然とそのような行動を獲得してくれるわけです。
センサー
ロボットはセンサーを使って自分の今の状態を認識します。
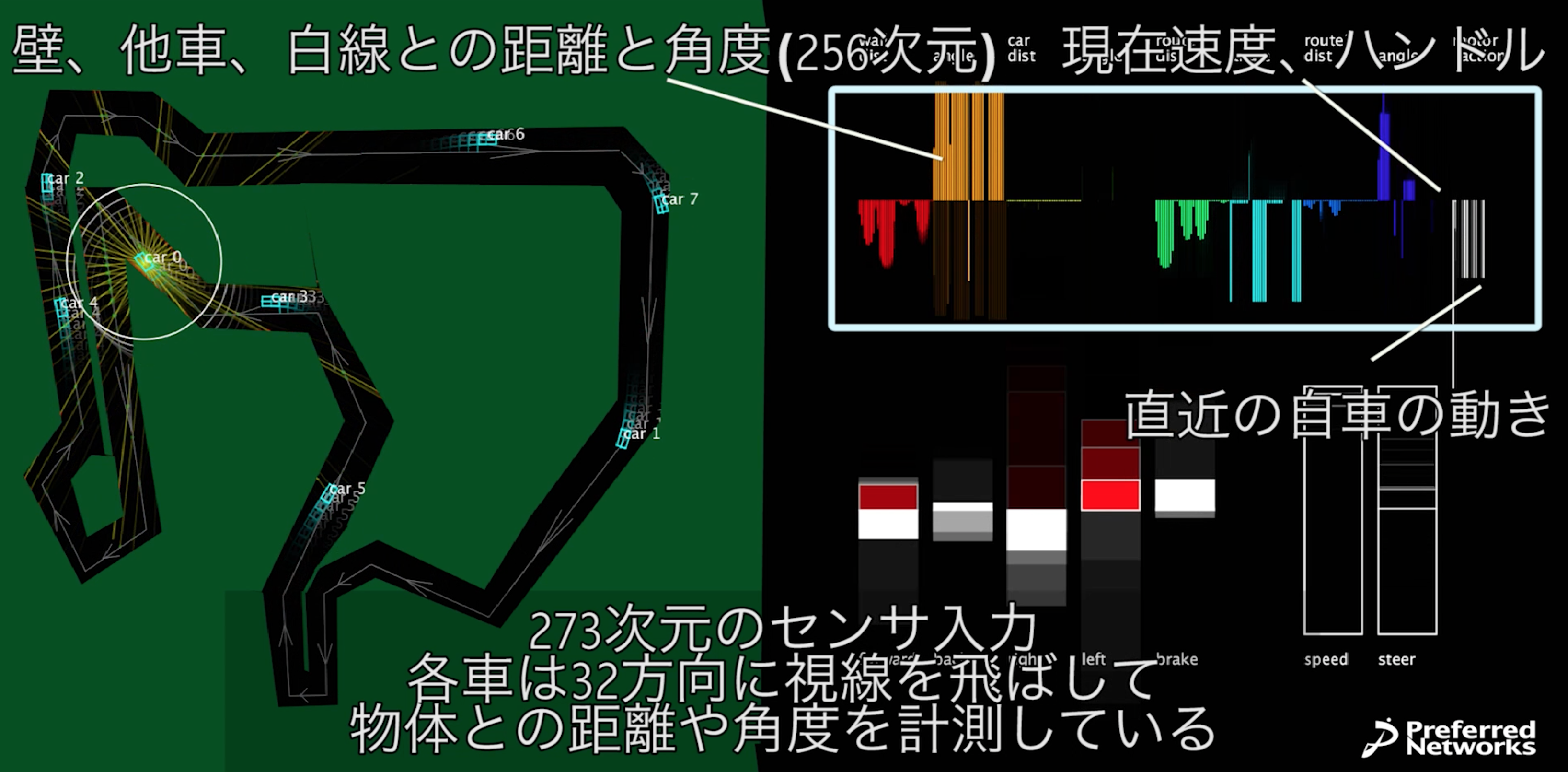
このデモでは、車は周囲32方向に仮想的なセンサビームを飛ばしていて、壁、他車、道路の中心線までの距離と角度を取得しています(図のcar 0が出している黄色い線がビームを表している。正確には遠距離センサ16本と近距離センサ16本に分かれている)。現実の自動運転車に搭載されているレーザー距離センサーをイメージしています。
そのセンサ情報に現在速度とハンドル位置、直近3ステップの自車の行動を加えて、合わせて273個の数を入力として受け取ります。右上のグラフにそれが可視化されていますが、車はこの情報だけから、今どの行動(アクセル、ブレーキ、左右ハンドル、バック)を取るべきかを決定しなければなりません。このような多様かつ多数のセンサ情報をうまく統合して適切な判断を行う問題はセンサフュージョンと呼ばれていて、これからのスマートデバイスや機械制御などに必須となる技術と考えられています。
ちなみに、学習開始時点では、ロボットはどのセンサ入力が何の入力を表しているのか、どの行動がどういう結果をもたらすのかを全く分かっていない状態から始まります。人間は「壁との距離」とか「アクセル」とか言われればその意味を理解できますが、ロボットは、まずはそこから学んでいかないといけないというハードな問題設定です。
Q-learning
強化学習には様々なアルゴリズムがありますが、今回はQ-learning + ε-greedyというベーシックな手法を使いました。
Q-learningでは、ある状態sである行動aをとったときに、将来にわたってどのくらいの報酬が得られそうかを表す関数Q(s, a)を学習します。
もし、Qが完全にわかっていたなら、状態sで取るべき行動は次のようにして決定できます。
行動の候補a1, a2, …があったとして、Q(s, a1), Q(s, a2), …を求め、最もQが大きくなったaを選ぶ。
Q関数は将来に渡る報酬の期待値をあらわすので、その行動が最も多くの報酬を生むことになります。
しかし、学習の開始時点では、Q関数は全くわかっていません。そのような状況では、Qが最大になるaを選んだとしても、それが最適な行動である保証は全くありません。Q関数を学習するためには、いろいろなシチュエーションを体験して、ある行動がどのくらいの報酬に結びつくのかを学ぶ必要があります。そのために、最初はランダムに動いて経験を貯めます。ある程度学習が進むと、(学習中の)Q関数が最大になるような行動が、そこそこ良い行動を表すようになっていきます。
そこで、ある割合εでランダムな行動を、1-εでQが最大になるような行動を選択します。これをε-greedy法といいます。「基本的には現在把握している最善の行動をとって、ときどき違うことも試してみる」というイメージです。
Deep Reinforcement Learning
Q-learningは古くから使われている手法ですが、昔は小さいサイズの問題にしか適用できていませんでした。例えばロボットが直面する状態が100通りしかなくて、行動も5通りしかないとしたら、Q関数は、100*5の表を埋めていくことで学習できます。Q(s, a)は表のs行a列目になるわけです。
ここで、状態1番のときに行動3番をとったら、10点の報酬がもらえて、状態が20番に移ったとしましょう。このとき、Q(1, 3) (状態1で行動3をとったときに将来得られそうな報酬の期待値)は、10 + max{ Q(20, a) }と考えることができます。10は今得られた報酬で、max{ Q(20, a) }は次の状態20のときに、現在わかっている最善の行動をとったときに得られる将来の報酬期待値になります。そこで、Q関数をあらわす表の1行3列目の値を10 + max{ Q(20, a) }に近づけます。この操作を繰り返すことで、この表は次第に正しいQ(s, a)に近づいていきます。
さて、今回のロボットは273成分の入力を受け取ります。これがロボットの認識する状態になるわけですが、各センサの値が0か1だとしても、2^273 ~ 10の82乗もの状態数になります。Q関数を表で表すならこれだけの数の行数が必要になりますが、とても不可能です。
そこで、表を使う代わりに、状態sを与えたら各aに対するQ(s, a)を出力するようなニューラルネットワークを使います。近年のDeep Learning(深層学習)技術の発展により、画像データのような数万成分の入力から、数千成分の出力を出すような巨大なニューラルネットが学習可能になりました。強化学習分野にDeep Learningを適用して有名になったのが、DeepMind社の発表したAtariのゲームをプレイする”DQN”(Deep Q-Network)です。
参考:昨夏のインターンでDQNの再現と改良に取り組んだ。
http://www.ustream.tv/recorded/53153399
今回の問題では273成分から5成分への7層(273-600-400-200-100-50-5)のニューラルネットを用いました。図の左下の白と赤のバーが、ニューラルネットの出力したQ(s, a)になります。
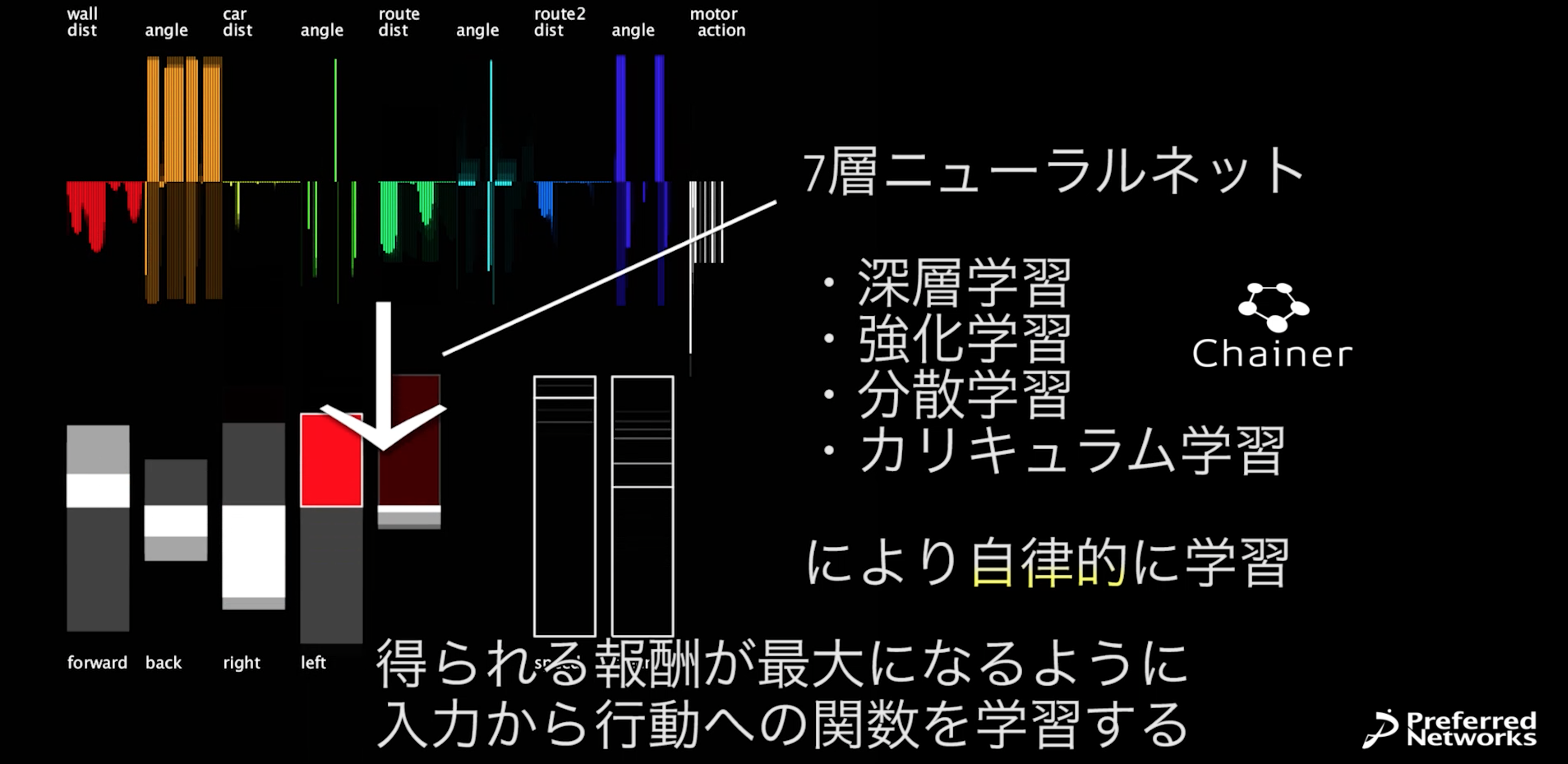
学習には、もちろん、昨日発表したあの、Chainerが使われています!!!Chainerサイコー!!
ニューラルネットが入力をどのように変換していくのかを解析することは容易でないですが、出現しない状態を見ないようにしたり、よく似た状態をひとまとめにするなどして効率的に情報処理を行っていると考えられます。この性質により、見たことがない状態に直面しても、そこそこ適切な答えを返すことが出来るという力(汎化能力)を持ちます。
動画中で突然現れた障害物にも対応できているのは、この能力のおかげと言えます。

四角い小さな障害物がランダムに存在していた環境で学習したら、丸い大きな障害物が突然現れる環境にも汎化して適応することが出来る。



