Blog
初めまして! PFN でアルバイトをさせてもらっている芝慎太朗です。普段は東京大学大学院で行動神経科学の研究をしています。僕が去年取り組んでいた、「車が自ら駐車場に向かい停止する」自動駐車プロジェクトについて報告します。まずはこちらのアニメーションをご覧ください。(アニメーションがうまく再生されない場合は画像をクリックしてください)

We implemented self-driving car that parks itself using deep reinforcement learning. The English slide is available at SlideShare!
背景
深層強化学習は、2015年から非常に注目され始めた人工知能技術であり、深層学習と強化学習を組み合わせたものです。深層強化学習によって、それまでできなかったような複雑なタスクにおいてもコンピューターが人を上回り始めました。プロ棋士を破ったことで一躍話題になった Google DeepMind による囲碁の人工知能 AlphaGo もこの技術を使っています。最近では スマッシュブラザーズにおいても威力を発揮し 話題になりました。
深層強化学習は制御タスクとの相性がよく、実際に PFN でもぶつからない車の自動運転やドローンの制御などに成功してきました。
PFN が CES 2016 で展示した自動運転(参照)では、アルゴリズムとして深層強化学習ブームの火付け役となった Deep Q Network(以下DQN)を用いています [Mnih et al., 2015]。ニューラルネットワークへの入力は、LIDAR(wikipediaによる解説)を模した近接物への距離と角度センサー、直前の行動、現在の車のスピードとステアリング(ハンドルの曲がり具合)でした。
しかし自動運転技術を現実に応用することを考えると、一般に距離センサーよりもカメラの方が安価という特徴があります。一方で、距離の計算が必要になるためカメラ画像の方が制御は難しくなると考えられます。実際、つい最近も ブラウザ上で動作するような簡単な自動運転デモ が公開されたばかりですが、これも距離センサーを使用しており、使用しているニューラルネットは3層程度の簡易なものです。
距離センサー・カメラそれぞれに得意・不得意な状況や利点・欠点があるので一概にどちらを用いるべきとは言えませんが、いずれにせよ、距離センサーに頼らずカメラ画像のみを用いて車を制御するようなアルゴリズムの研究開発は非常に重要です。
本プロジェクト
このプロジェクトでは、距離センサーではなく、車に取り付けられたカメラによる主観的な画像の入力によってend-to-endのアルゴリズムで車を制御できないか、ということに挑戦しました。具体的なタスクとして選んだのは駐車です。すなわち、車を駐車スペースに移動して停止させます。
アルゴリズムとしては DQN の改善版である Double DQN を使用しました。Double DQN は行動価値の見積もり値である Q 値の過大評価を防ぎ、ニューラルネットの発散を防ぐことで学習を安定させるという特徴があります [Hasselt et al., 2015]。詳しくは解説スライド(この投稿の最後にリンクが貼ってあります)や元論文をご覧ください。
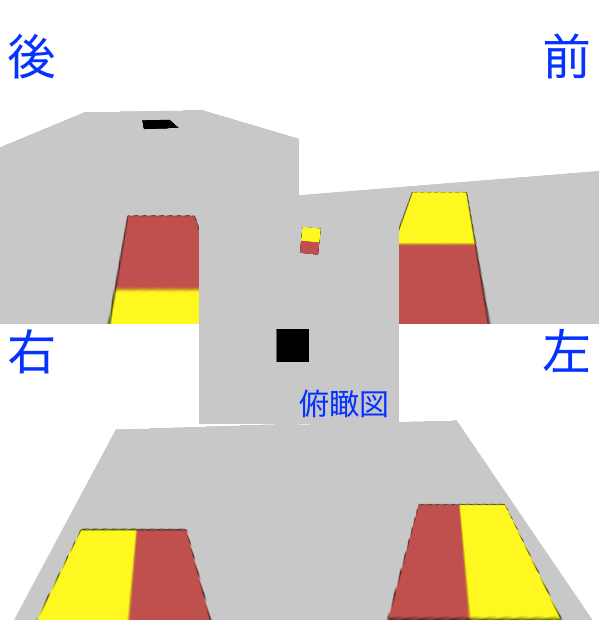
まずは環境の定義です。今回は実機や既存のシミュレータを使用せず、簡単な車の物理シミュレータを自分で実装しました。このシミュレータはアクセル、ブレーキ、ハンドルの曲がり具合を受け取り、牽引力、空気抵抗、転がり抵抗、遠心力、制動力、コーナリング力を計算し、車の位置、速度、加速度を更新します。車や駐車スペースの大きさと、車が探索できる地面の範囲なども定義しました。次の図は、シミュレーションされた環境を上から見た俯瞰画像です。黒い長方形が駐車スペース、赤と黄色の長方形が車(黄色が前)になります。

次にエージェントへの入出力を定義します。エージェントは環境の状態を入力として受け取り、アルゴリズムにしたがって適切な行動を選択します。現実世界に例えるなら車に乗っている人に相当するでしょう。行動はアクセル、ブレーキ、ハンドルを左右に曲げることの組み合わせで全部で9種類用意しました。状態としては、環境を車から見た主観画像と、現在の車のスピードとステアリング(ハンドルの曲がり具合)を使用しました。つまり、車の現在位置や駐車スペースまでの距離を直接知ることはできません。
主観画像は、車を中心に3方向または4方向に設置されたカメラ画像を用意し、車の周りをぐるりと見渡せるようにします。次の画像はカメラが4台の場合の主観画像です。画像の大きさはニューラルネットに入力する直前で 80 x 80 に縮小します。わかりやすいように中心に先ほどと同様の俯瞰画像を載せました。
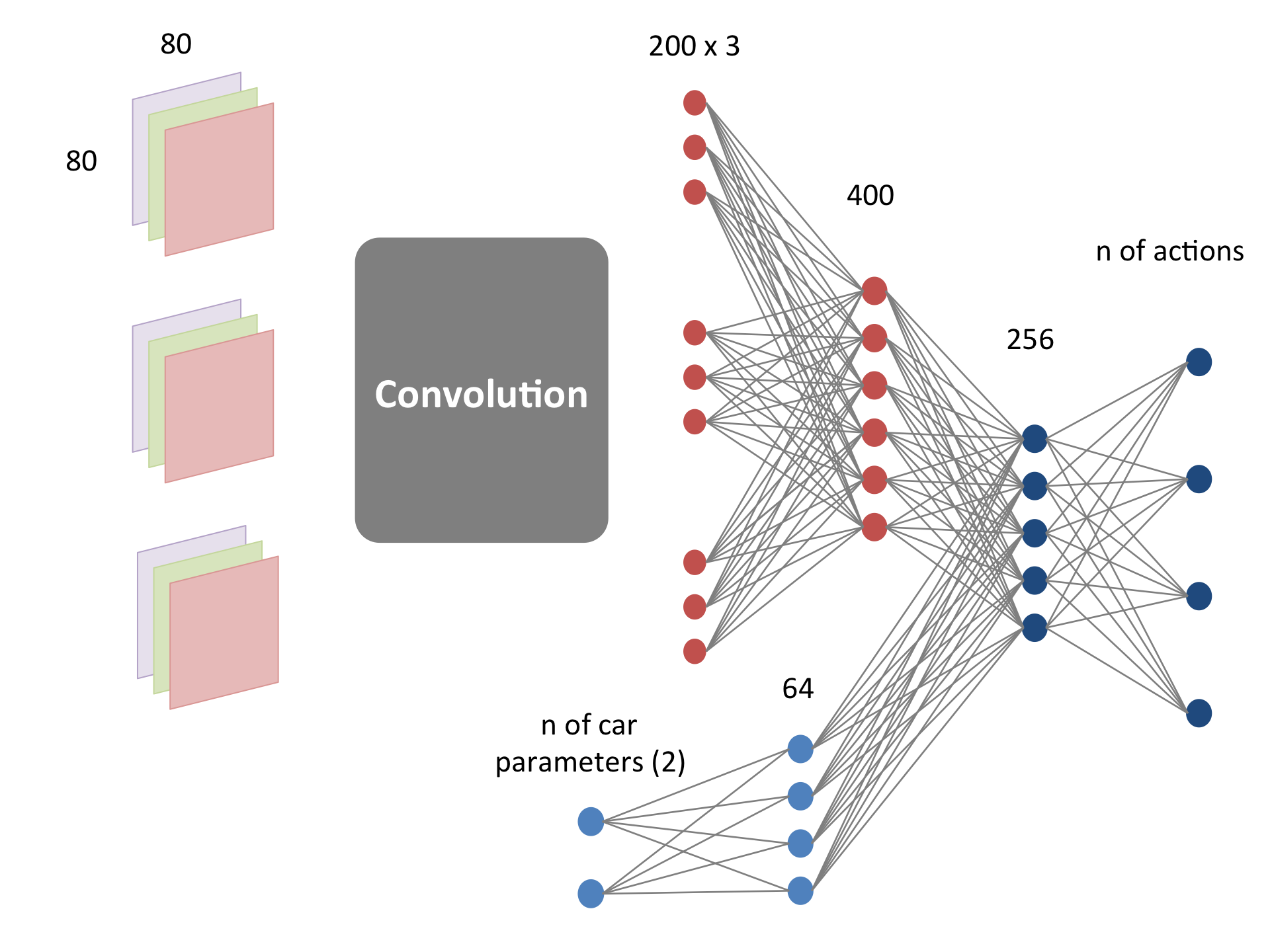
エージェントは、画像の入力に合わせて適切な行動を選択し、車を駐車スペースに導いてそこで停車することが求められます。状態がカメラ台数分の画像と、画像でないパラメータ(現在の車のスピードとステアリング)からなるため、ニューラルネットの構造を工夫して以下のようにしました。この図はカメラが3台の場合に使用されたニューラルネットワークです。図中の Convolution とは、画像を処理するための畳み込みニューラルネットを示します。
最後に報酬を定義しておきます。「車が駐車スペースに向かい、その中で停止する」、すなわち「車ができるだけ長く駐車スペースの内側にいる」ことを学習するような報酬の与え方を考えます。いろいろな設定を試しましたが、最終的に
- 車が駐車スペースの内側にいる場合、+1
- 車が地面の外にいる場合、-1
- その他の場合、0.01 – 0.01 * ゴールまでの距離
というふうに設定してみました。
その他の細かい設定や、他に試した報酬の設計などは末尾のスライドをご覧ください。
結果
GeForce GTX TITAN X 上で約一週間ほど学習を回し続けた結果、冒頭で示したように、車が自動で駐車スペースに向かい停止するように学習できました。次のアニメーションは冒頭と同じもので、左が車の軌跡、右が実際にニューラルネットワークに入力された画像です。
しかしながらやはりタスクの難しさもあって、このまま学習を続けていくと車が地面をぐるぐる回り続けたり、パラメタによっては学習途中でニューラルネットの出力が発散してしまったりという場合もありました。こちらも詳細はスライドを見ていただければと思います。
考察
深層強化学習を用いて、主観画像の入力から自動駐車を学習できました。画像を入力して車を制御するのは、距離や角度のセンサーよりも一段階難しいタスクです。実は、このプロジェクトも距離などを入力にして学習させるところから始めました。距離を直接入力した場合には安定してすぐに学習できたものの、主観画像では Q 値の発散や、うねうねと動き続ける車が誕生したりとなかなか安定しませんでした。
原因として考えられることの1つに、畳み込み層で車や駐車スペースの場所がうまく検出しきれていない可能性があります。先にCNNから位置を回帰するような事前学習をおこなってその重みを初期値として使うことや、一度 CNN 部分の出力を可視化してみることも有用でしょう。
また学習を安定させるために、アルゴリズムの変更も効果的かもしれません。例えば A3C [Mnih et al., 2016] や TRPO [Schulman et al., 2016] を使ってみたり、モンテカルロ法と組み合わせた学習などは試す価値があると考えられます。
実際にはいきなり始めから主観画像を入力したわけではなく、上で少し述べたように、簡単なタスクから徐々に難しくしていました。また、報酬の設計を変更しつつ、駐車スペースの位置や車の初期設定を変えながらカリキュラム学習をしたりと細かい実験を試しています。これらの詳細が知りたい方は上記のスライドを見ていただければと思います。
まとめ
本プロジェクトの結果はまだ様々な状況で完全に対応できるものではありませんが、深層強化学習によってカメラ画像のみで自動駐車が実装できる可能性を示したものだと言えます。今後の方向性としては、学習アルゴリズムを変更して学習を安定させたいです。シミュレーションだけではなく、実機でも実現できれば非常に面白いと思います。
僕は現在も他のプロジェクトに取り組みながらアルバイトを続けています。初めからプログラミングや強化学習ができたわけではなく、自分で勉強しつつ、わからないところをメンターに教えていただきながら、大変恵まれた環境で進めることができたプロジェクトでした。学生の皆さんも興味があればアルバイトやインターンに積極的に飛び込んでいってみてはいかがでしょうか。



