Blog
先日リリースさせて頂いたとおり,MN-2の構築を行っています.MN-2は最新世代の,1024基のNVIDIA(R) V100 GPUが計算力の主力となります.現在利用しているMN-1およびMN-1bにおいて1024基のP100と512基のV100を稼動させていますが,MN-2の追加によりGPU数換算で合計2560基となり,保有計算力を大幅に強化しました.とはいえ,現時点ではKubernetesをはじめとしたソフトウェアサービススタックのセットアップ中であり,GPUは主にベンチマークを実施して状態確認を行っている段階です.
PFNでリサーチャをやっている,土井裕介です.最近はリサーチ業務はあまりやっておらず,社内インフラ関係の全体の世話役のような業務が主担当になっています.今回,物理構築が一段落したのでBlogにてMN-2の概要やポイントを紹介させて頂きます.

構築中のMN-2
なぜMN-2を作るのか?
よく,「なぜPFNは自前インフラを持つのか?」というご質問を頂きます.自前インフラを持つ理由にはいろいろな側面があって一言では説明できないのですが,土井としては一つ,ハードウェアの全コントロールを握りたいから,という理由があります.例えば,計算のパフォーマンスが出ないという時に,どこをどう改善すればいいか,改善するとしてどのようなアプローチが存在するかを考えます.このとき,実際のハードウェアが上から下まできちんと見えるか,それともクラウドのむこうにあるのかで,取ることができるアプローチの幅にかなりの差が生まれます.特に今回はネットワークも含めて全て自前となっているため,見ることができる計測点が増えており,深層学習に向けたインフラサイドの研究開発の基盤としても活用できると期待しています.
さらに,今後 MN-Coreを使った計算機クラスタ(MN-3)も予定しています.MN-Coreは少なくとも当面はクラウドには置けないので,これを活用するためには自前のインフラを持つ必要があります.電源・冷却・ネットワーク・ストレージを含めて共用する前提で,GPUクラスタ (MN-2) を事前に作ることで,MN-3の構築に必要な経験をPFN社内で貯めている,という側面もあります.
MN-2の設計のポイント
MN-2の設計にあたり,いろいろなことを考えました.考えたことの大半は実現性との兼ね合いや時間との戦いの中で没になりましたが,一部実現したポイントもあるので,かいつまんでご紹介させてください.
ラック設計・電源・冷却
今回採用したGPUサーバは,8GPUを1台に搭載しており,定格で1台あたり3.5kWの消費電力です.床の耐荷重や電源供給・排熱等の問題,またMN-3の先行モデルとしての役割もあり,1ラックあたりの搭載数は4ノードとしています.1ラックあたり4ノード32GPUで定格14kWという計算になります.今となってはこの熱密度は高い方ではありませんが,純粋な空冷設備としてはそれなりに高い部類に入ると思っています.MN-2ではこのGPU計算ラックを連続で16ラック並べたものを背面を対向として2列置いています.合計32ラック128ノードになります.
MN-2クラスタを置かせて頂いているJAMSTEC横浜研究所シミュレータ棟は,冷気が床下から吹き出して天井側から熱気を回収する構造になっています.MN-2のGPUの排熱が他のGPUや地球シミュレータに与える影響を最小限とするため,背面(熱風が出る側)を対向させ,ラックの両端にドアを設置して,熱気が横方向に流れないように閉じ込めています.上方は空けてあるので,下から来る冷気の勢いと対流効果で熱の大半は天井側に送られるデザインです.さらに,ラック背面にフィンを設置して熱風が対向のラックに回りこみにくいようにしています.

GPUの排熱を上方に逸らす整流板をつけた状態
実際に全GPUに対して模擬的な負荷をかけて稼動させてみましたが,hot側の温度は高くなったものの,cold側の温度はほぼ影響なく,想定通りの結果となりました.
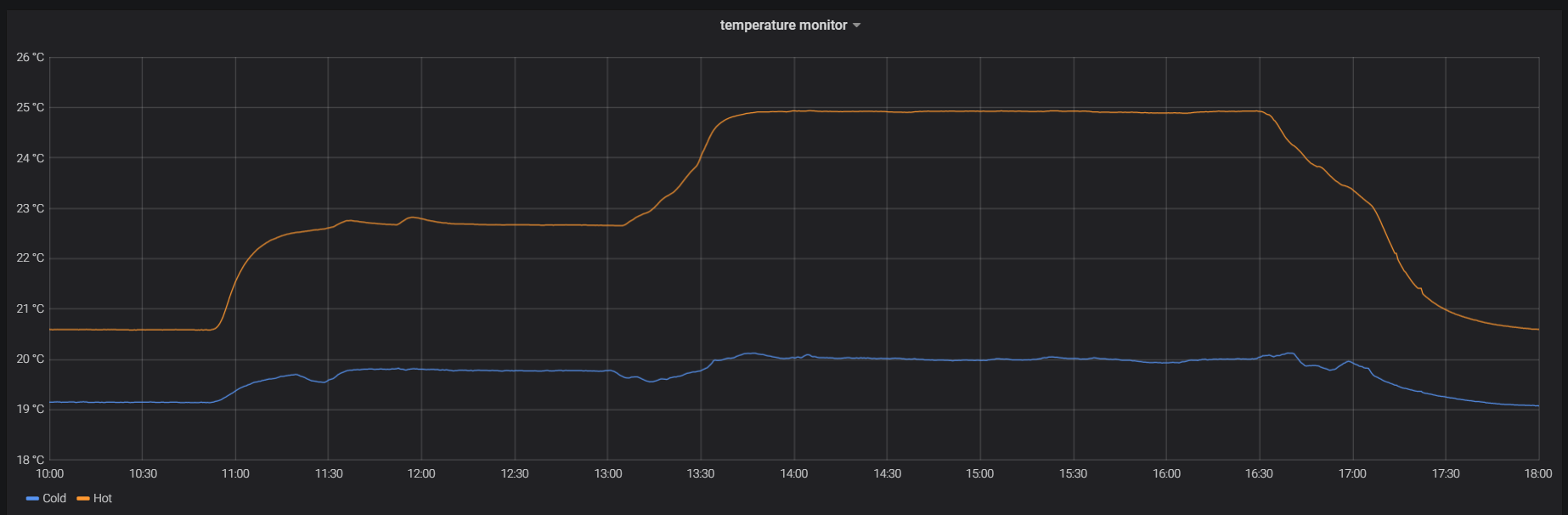
高負荷試験時の温度変化 (下段: 吸気/COLD側 上段: 排気/HOT側)
ネットワークとインターコネクト
HPCにおいては,計算機を相互接続するインターコネクトは重要です.深層学習においても同じことが言えますが,例えばさまざまな種類の巨大なシミュレーションを連続的に分散実行するようなスーパーコンピュータのワークロードと,学習途中のパラメータを適時同期する深層学習のワークロードにおいては、求められる性質は異なります.深層学習において支配的なデータ通信は,主にデータセットのロードとパラメータ交換であり,パケットサイズがおおきくなり,バンド幅が重要になりがちな傾向があります.
PFNでは技術吟味の結果,ファイルシステムはいわゆるHPC向けのファイルシステムではなく,Hadoopなどで使われているHDFSをメインに利用して,ローカルのデータキャッシュを活用する方向で検討しています.このことから,データセットの読み込みはEthernetが中心となります。従来多く使われてきた(MN-1でも利用している)InfinibandとEthernetの両方で広帯域の確保はPCIeのレーン数の制約から難しい場合があります.また,InfinibandとEthernetの両方に投資することは機能的には二重投資となることもあり,MN-2では冒険的に,インターコネクトの役割も全面的にEthernetとして,RoCEv2(RDMA over Converged Ethernet)を採用しました.パフォーマンスは,一部のInfinibandが得意としているshort packetの領域を除き,Infinibandと遜色ないことを確認しています.
今後
MN-2としての本格稼動は7月を予定していますが,先行して現状のクラスタの概要を紹介しました.
今後MN-3の構築がはじまる見込みで,それにあわせてPFNではインフラ人材も募集中です.特に運用・改善の領域において,Kubernetes上で動作する深層学習のワークロードと,MN-Coreを含めた先端ハードウェアとを両方睨んで最適化を行う,というアツい仕事が待ってます.我こそは! という方は,是非弊社ホームページにある採用の欄からご連絡いただくか,個人的にご存知のPFN社員なり,土井 (doi@preferred.jp) までご連絡ください.
Area
Tag