Blog
PFNでは自然言語処理(NLP)による研究開発にも取り組んでいます。
自然言語は人にとって最も身近なインターフェースのうちの一つです。
弊社ではこれまでにもロボットへの言語指示(ICRA 2018, CEATEC 2018)などの研究開発の成果を発表してきました。
先日7/28-8/2にイタリアのフィレンツェにて、自然言語処理のトップ国際会議ACL 2019が開催され、弊社からも佐藤元紀と小林颯介が参加しました。今回はその様子を論文紹介とともにお伝えしたいと思います。本記事は2名で協力し執筆しています。

(写真:会場となったバッソ要塞)
また、佐藤元紀が東北大学の鈴木潤氏・清野舜氏と執筆した論文 “Effective Adversarial Regularization for Neural Machine Translation” を口頭発表しました。この論文についても紹介します。
※佐藤が学生時代に行っていた研究です。
なお、ACL 2019では口頭発表された論文については基本的にビデオが公開されています。以下のリンクからアクセスできます。
- 動画📹https://www.livecongress.it/sved/evt/aol_lnk.php?id=60B5FD70
- ACL 2019: http://www.acl2019.org/EN/index.xhtml
- ACL 2019 proceedings: https://aclweb.org/anthology/events/acl-2019/#p19-1
ACL 2019 概要
まずACL 2019の概要について紹介します。
2019年の投稿数は2905件で去年の投稿数1544件よりも大幅に投稿数が増えていました。前年までも増加傾向にありましたが、今年は一気に跳ね上がりました。相並ぶNLPのトップ会議であるNAACL(6月)と来るEMNLP(11月)でも今年は投稿数の倍増が見られました。
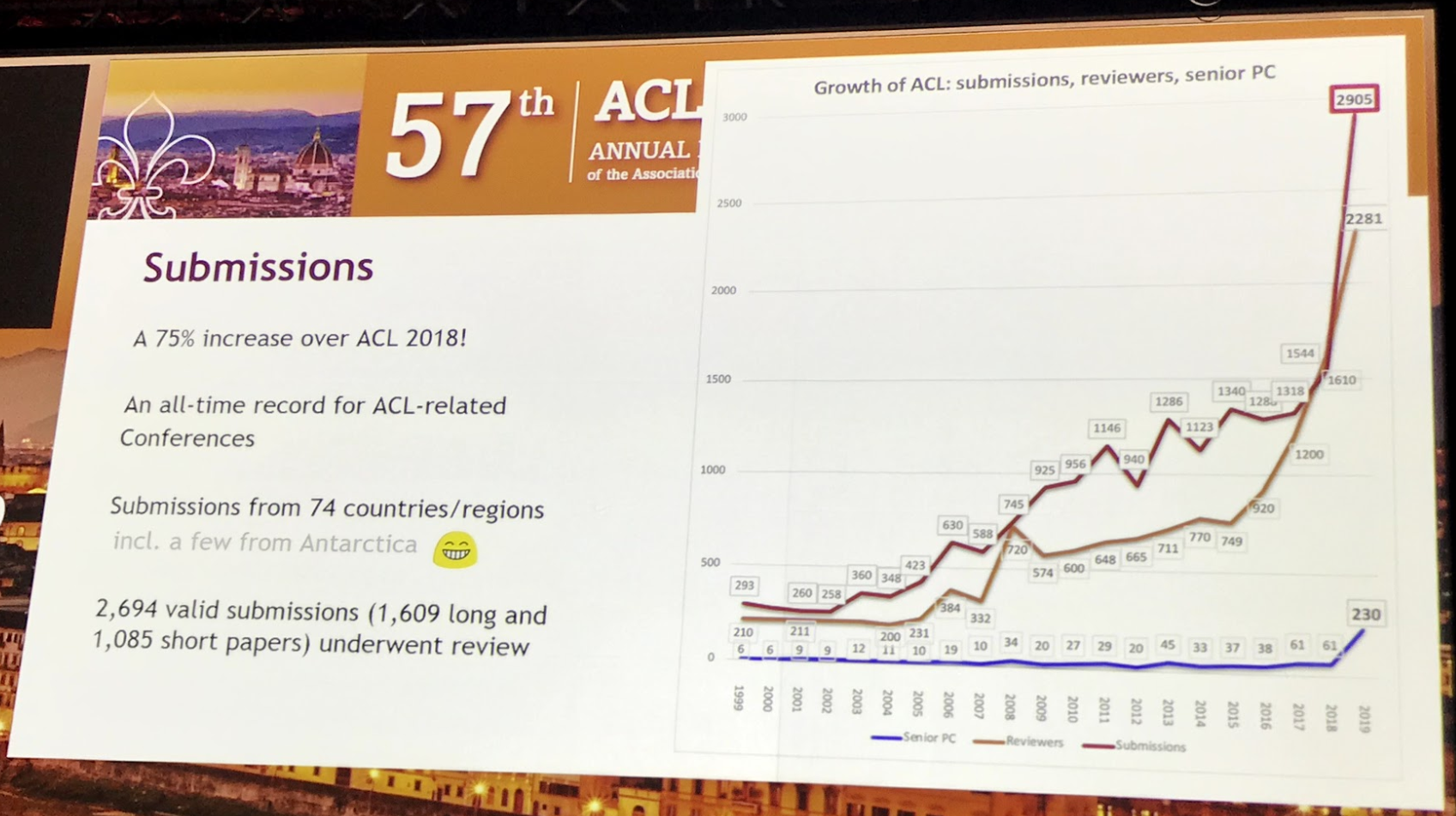
(写真:ACL 2019 Openingより)
分野別の投稿数については次の分野が順に人気でした。
- Information Extraction and Text Mining (9%)
- Machine Translation (8%)
- Machine Learning (7%)
- Dialogue and Interactive Systems (7%)
- Generation (6%)
際立って人気な分野はありませんが、Machine Translation(機械翻訳)やDialogue and Interactive Systems(対話システム)が昨年に比べて微増しており、また、Generation(生成)については昨年はシェアが4%ほどだったものが6%になりました。投稿数の増加も相まってトータルでは3倍近くの論文が投稿されるようになったホットな分野だと言えるでしょう。
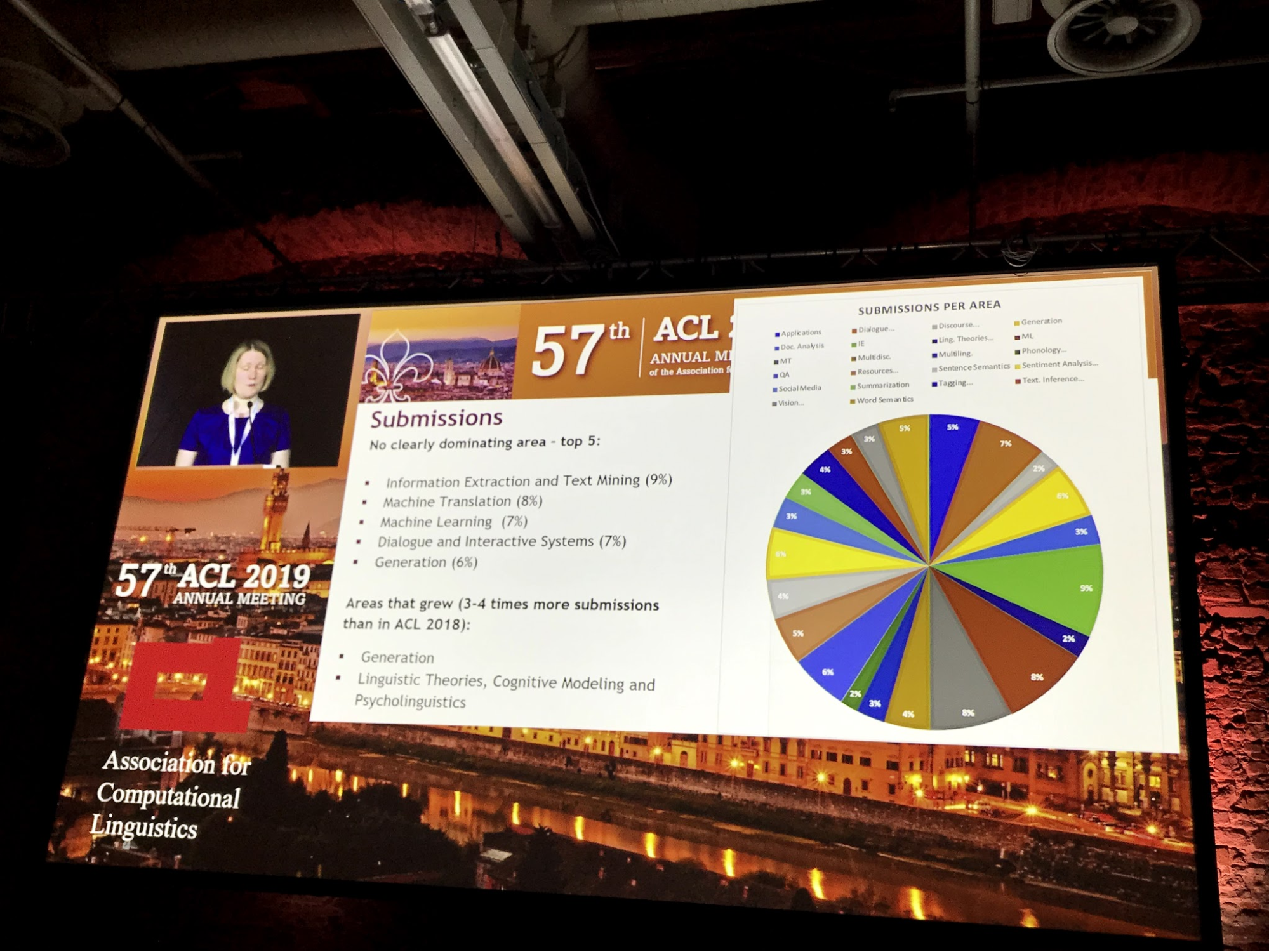
(写真:ACL 2019 Openingより)
投稿や採択の本数は増えましたが、採択率はLong paperで25.7%、Short paperで18.2%と概ね例年どおりでした。
以下では、参加した佐藤、小林が気になった論文や特徴的な論文の紹介をしていきます。
離散的構造
NLPでは、品詞タグ付け、構文木解析、単語アライメントなど系列や離散的な構造を扱うタスクが多いです。構造内で依存性のある入力や予測をいかに考慮するか、膨大な出力空間の中で教師データをいかに活用するか、などの興味深い課題が存在します。この分野で発展してきた手法は、時系列予測やデモンストレーションからの制御学習など、共通の性質を持つような他の分野でのタスクに応用できるかもしれません。
ACL 2019では、離散的構造を持った潜在モデルについてのチュートリアル “Latent Structure Models for Natural Language Processing” が行われ、注目度の高いトピックとなっていました。
- Latent Structure Models for Natural Language Processing スライド資料: https://deep-spin.github.io/tutorial/acl.pdf
以下のスライドでは、End-to-Endのニューラルネットワークの中間表現として離散的な構造をどう扱うかについて説明されています。End-to-Endの枠組みで離散的な構造を扱うには、基本的には演算を一貫して微分可能にすることが必要です。そのためにこれまで提案されてきた手法について、REINFORCEからSparseMAPまで幅広くよくまとまって紹介されていました。

(ACL 2019 チュートリアルの図)
ここでは、カテゴリカル分布を含む計算グラフを微分可能にするテクニックを紹介します。
まず、カテゴリカル分布からサンプリングを行う実装方法の1つとして、Gumbel-Max Trickという方法が知られています。softmax層に入力する前のスコアベクトルを s とすると、Gumbel分布G(0, 1)からサンプリングされるノイズベクトル ε を用いてargmax(s + ε)を求めることは、カテゴリカル分布softmax(s)から1つの要素をサンプリングすることと等価になります。
(なお、ε ~ G(0, 1) は ε = -log(-log(u)), u ~ Uniform(0, 1) でも計算できます。)
また、このargmaxをとる前の s + ε について温度パラメータ τ を導入したsoftmaxとして softmax((s + ε) / τ) を考えると、τ → 0 の場合には、argmaxによるone-hot ベクトルとこの値が等しくなることが分かります。このノイズ付きのsoftmaxの出力をそのまま、サンプリングによるone-hotベクトルの代わりとして用いる(continuous relaxation)ことで、テスト時の実際のサンプリングでの計算とは少し異なるものの、訓練用の微分可能な計算グラフを実現できます。サンプリング結果に対して単に埋め込みベクトルの辞書引き(one-hotベクトルに対する行列計算)を行う場合などには、このようなrelaxationが可能になります。
より発展して、実際にサンプリングをした上で擬似的にbackpropagationを可能にするStraight-Through Gumbel Estimatorという方法もあります。forward計算の際には、上記のノイズ付きsoftmaxからサンプリングしたone-hotベクトルを用います。一方、backward計算の際には、one-hotベクトルをサンプリング前のsoftmax出力へとすり替えて伝播を行います。
不思議なトリックではありますがこれでモデルは問題なく学習できることも多く、このStraight-Through Estimatorのアイデア自体はニューラルネットワークの量子化などでも活躍しています。
次に、ACL 2019のBest Long Paperについて紹介します。
- Bridging the Gap between Training and Inference for Neural Machine Translation
https://www.aclweb.org/anthology/P19-1426
RNNなどのニューラルネットによる文生成モデルの訓練について改善を提案した論文です。
よく使われる文生成のモデルは自己回帰モデルになっており、ある位置で単語を予測・生成した後にはその単語を入力として次の単語を予測し、その流れを繰り返して文生成の推論を行います。一方で訓練の場合には、次の単語を予測する際に入力される単語は、「前位置で予測した単語」ではなく、教師データの正解文から取り出された「前位置の正解の単語」です。この訓練の方式は広く使われており、teacher forcingとも呼ばれています。
このように、訓練時には常に1つ前の位置までの正解の単語列(の一例)を常に見ることができる一方で、テスト時の推論では再帰的に自身の予測結果に基づく文生成を行う必要があります。このようにテスト時の設定と異なるようなデータ分布でしか訓練ができていないexposure biasと呼ばれる問題があり、テスト時の性能低下につながるとこれまでも指摘されてきました。
この論文では、常にteacher forcingの「正解単語での文脈」で訓練をするのではなく「予測単語での文脈」による訓練を確率的に織り交ぜる方法について提案しています。その際、入力する文脈として使う(予測)単語は、単に予測分布からargmaxで選ぶよりはサンプリングを行ったほうがよく、また、先に文全体をビームサーチやサンプリングなどで生成した上で単語を選ぶのも効果的だと示しています。また、学習初期には正解単語を多く使い、終盤ではより多く予測単語に触れさせるようなスケジューリングも行っています。これまでにもBengio et al. (2015)やRanzato et al. (2015)から研究されてきたテーマでしたが、文レベルの拡張などを含めた統合的な実験で良好な結果を示せた点、その他の文生成タスクへの応用可能性への期待から今回の選定につながったようです。
Adversarial Training
次に、今回ACLに採択された佐藤の論文を紹介させてください。
- Effective Adversarial Regularization for Neural Machine Translation
https://www.aclweb.org/anthology/P19-1020
スライドは以下のリンクで公開しています。
ニューラルネットワークの訓練時に、入力データを少し変化させた状態で訓練を行うと汎化性能が向上することがあります。その一例として、モデルの出力の正解に対するロスを大きくしてしまうような敵対的なノイズ(Adversarial perturbation)を入力に足し合わせて訓練を行うAdversarial Training (Goodfellow et al., 2015)という方法があります。また、さらに発展したVirtual Adversarial Training (Miyato et al., 2015)という手法もあります。こちらは正解の教師データは必要なく、出力の分布を最も大きく動かすような敵対的なノイズを用いて訓練を行います。教師データのない入力データを用いて訓練ができるため、半教師あり学習の手法として有用です。
(なお、Adversarial Trainingという用語は敵対的なモデルや勾配を用いる学習方法全般について使われますが、本記事では上の訓練方法を指す狭義の意味で使います。)
これらはまず画像認識のタスクで有効性が確かめられ、その後[Miyato et al. (2017)]がテキスト分類タスクにおいてLSTMベースのモデルに適用し、当時の該当データセットにおける世界最高性能を達成しました。画像のタスクでは、画像の入力そのものにノイズを足し合わせていましたが、言語のタスクでは生の入力が単語(さらに意えば文字)の記号のため難しく、代わりに単語ベクトルへと埋め込んだ後にAdversarial perturbationを足し合わせて適用しています。
こうしてテキスト分類のタスクではAdversarial Trainingが有効であることは知られていたのですが、機械翻訳を始めとした文生成のタスクでは適用例がありませんでした。ここに取り組んだのが本研究になります。
シンプルには「機械翻訳でAdversarial trainingは効果的なのか」という問いですが、機械翻訳のタスク及びモデルでの適用に関してはいくつか設定が考えられるため、それらを実験的に確かめることで実用性を高めました。
特に以下の3つの側面に対して実験を行っています。
- LSTMとTransformer両方のモデルで効果があるのか?
- 敵対的なノイズの計算にはAdversarial TrainingとVirtual Adversarial Trainingのどちらを使うべきか?
- Encoder側(原言語文)とDecoder側(目的言語文)でともに単語ベクトルの入力部分があるが、どこにノイズを加えるべきか?
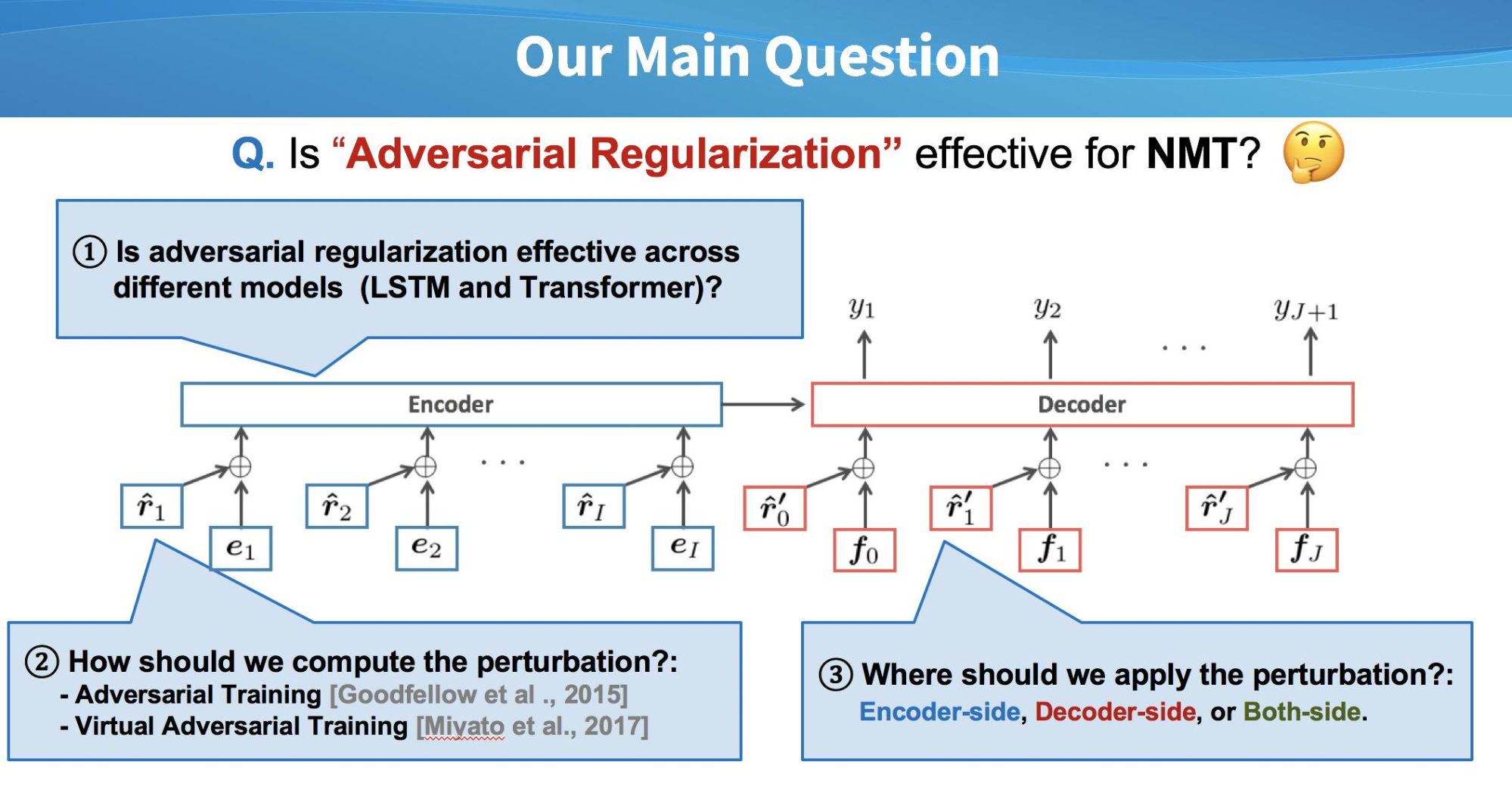
結果として、Transformer + Virtual Adversarial Training の組み合わせが良く、ノイズを加える場所は、EncoderとDecoder両方に入れるのが効果的でした。
Adv (Adversarial Training) と VAT (Virtual Adversarial Training) の比較ではAdvの方が効果的でしたが、これは [Miyato et al. (2017)] でのテキスト分類の結果 (論文中 Tables 6)と一致しました。Advの欠点として、ラベル情報からの簡単な変換でノイズを生成しているため、モデルがAdvesarial Perturbation付きの入力に対して変にoverfitしてしまうのではないか、と[Kurakin et al. (2017)]は議論しています。VATはノイズ計算にラベル情報を使っていないためこの現象は起きず、今回の実験でもVATの方が性能が上がっているのではないかとか思っています。
現在、機械翻訳など文生成のタスクではLSTMからより性能の出やすいTransformerへと人気が移っていますが、Adversarial Trainingを適応した場合にはどちらのアーキテクチャでも同様の性能向上が見られました。
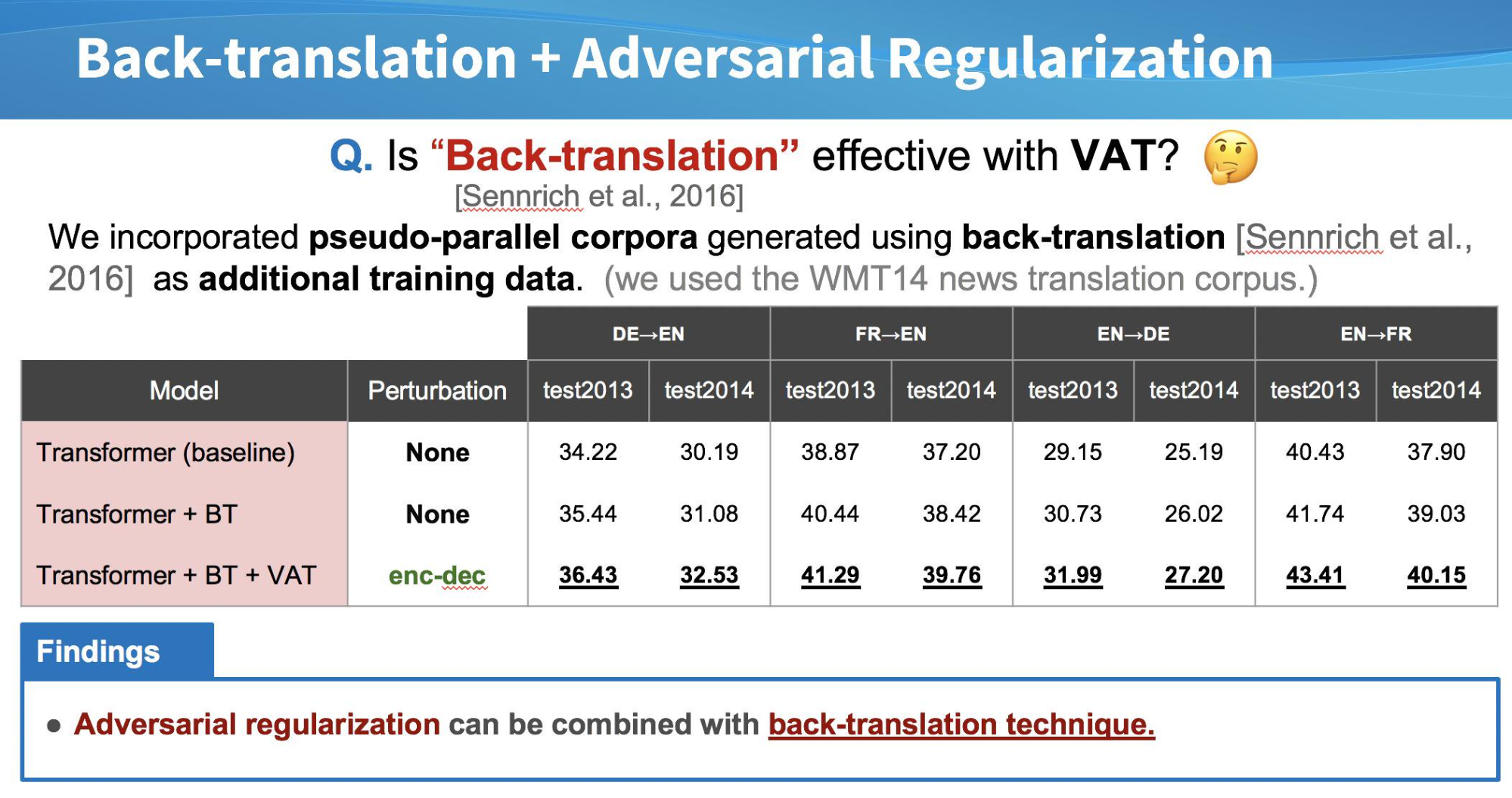
また、Virtual Adversarial Trainingは半教師あり学習にも適用できることを上で紹介しました。今回は、機械翻訳タスクの半教師ありの手法として効果的なBack-translation [Sennrich et al., 2016]と組み合わせることで、さらに大きく性能が上がることを確認しました。関連タスクに取り組む機会があればぜひ試してみてください。
マルチモーダルタスク
次に新しくデータセットを作った研究の中で気になったものを紹介します。
- Expressing Visual Relationships via Language
https://www.aclweb.org/anthology/P19-1182
Adobe Researchの方々の研究で、RedditのPhotoshop Requestというページから「元画像」「編集リクエスト文」「編集された画像」の3つ組を収集しデータセットとして公開したものが発表されていました。先行研究の似たデータセットとして、動画中のフレームから抜き出した2枚の写真の違い(例: 青色の車が無くなった)をデータセットとして公開しているSpot-the-Diffや、2枚の画像の関係について説明したテキストが付与されているNLVR2があります。
論文の実験では「元画像」「編集された画像」を入力としてリクエスト文の生成を行っていました。二種類の画像の差分や関係性について表現するような言語生成タスクになっています。また、今回のデータでは、別のタスクとして編集リクエスト文から画像の編集を行う実験も考えられます。難易度はかなり高そうですが、今後の研究でテキスト指示によって画像を自由に編集できる研究がさらに発展すると面白いなと思いました。

([Tan et al. 2019]の図より)
セグメンテーションとの同時学習
最後に紹介する興味深いトピックは、テキストのセグメンテーション(分かち書き)を学習しながら、そのセグメンテーションで分割された系列で目的のタスクのモデルを学習していく話です。
NLPではCNN、RNN、Transformerなど様々なニューラルネットワークのモデルを使いますが、これらに共通している一般的な処理があります。与えられたテキストはまず始めに何らかの離散トークン列に変換し、各トークンに割り当てられた埋め込みベクトルを組み上げていくことで構成的な意味表現を得ています。また、機械翻訳のように文を生成する際にも全テキストが一気に生成されることはなく、トークンごとに順番に生成されていきます。
このように言語処理の根幹をなすのがトークン列への変換処理、セグメンテーションです。このセグメンテーションをどうするかによって、モデルの出力や性能が変わってきます。典型的なセグメンテーション処理としては、スペースでの分割や、Byte Pair Encoding (Sennrich et al., 2016)による分割、あるいは1文字ごと分割してしまって文字ベースでテキストを処理するという手もあります。日本語や中国語のように空白文字での分かち書きが付いていない言語では、なおのことどうすべきか奥が深いテーマです。英語にしても、スペース分割そのままに doing という文字列をひとかたまりとして見るか、あるいは do+ing として見るか、どちらがより良いのか(特に、ある機械学習モデルの性能をいかに効率よく高められるのか)は自明ではありません。なんにしてもある1つのテキストに対して様々なセグメンテーションというのが考えられ、NLPに関する工学としても言語獲得の研究としても興味深いテーマになっています。
以下の2つの論文では、テキストの出現確率を計算する言語モデルについて、同時にそのテキストの様々なセグメンテーションのそれぞれを考慮して周辺化で計算を行うモデル(と、その学習によって得られるセグメンテーションモデル)の構築を目指しています。
- Learning to Discover, Ground and Use Words with Segmental Neural Language Models
https://www.aclweb.org/anthology/P19-1645 - Training Hybrid Language Models by Marginalizing over Segmentations
https://www.aclweb.org/anthology/P19-1143
様々なセグメンテーションで訓練ならびに推論を行うことで、分割の曖昧性に頑健になったり様々なデータのパターンに触れることによる汎化の効果が期待できます。様々なセグメンテーションを考慮するというのは、例えば、次に his という単語が出現することを予測する場合に {his, h+is, h+i+s, hi+s} という分割の異なる複数のパターンについて計算を行っていくような処理です。しかし、長いテキスト上では可能なセグメンテーションそれぞれで全計算をやり直していては計算量が爆発してしまいます。この問題を緩和するために、論文では、「文脈側のテキストに関しては分割を考慮せずに全て文字ベースで扱う」というアイデアを活用しています。上のように予測(生成)する際には4パターン考慮した his ですが、この方法であれば、その次に繋がるテキストについて考えるときには、どういう分割パターンの his なのかが条件部に入らない式で一括で計算できます。その他、あるトークンの確率計算に際して典型的なsoftmax層でのスコアと文字ベースデコーダでのスムージング的なスコアを混ぜ合わせる構造や、セグメンテーションの各トークンの長さに対して正則化をかけるなどの効果的なテクニックも提案されています。
その他以下の論文でも、テキスト分類を文字と分割トークンの併用で解くモデルの訓練時に、様々なセグメンテーションで訓練データを入力することで分類性能が向上したと報告されています。昨年のACLで発表されたSubword Regularization (Kudo, 2018)のように、多様なセグメンテーションによる汎化性能向上を示す面白い論文でした。
- Stochastic Tokenization with a Language Model for Neural Text Classification
https://www.aclweb.org/anthology/P19-1158
上ではセグメンテーションについて紹介しましたが、系列に関して曖昧性が生じる他の代表的な例としては、音声認識による書き起こしの予測結果が挙げられます。そのような曖昧性を残した複数の系列パターンを表すラティスに対して適用可能なTransformerとして、attentionのマスク処理やpositional embeddingに工夫を凝らした亜種を提案する論文もありました。
- Self-Attentional Models for Lattice Inputs
https://www.aclweb.org/anthology/P19-1115 - Lattice Transformer for Speech Translation
https://www.aclweb.org/anthology/P19-1649
おわりに
今回は ACL 2019における論文をいくつか紹介しました。言わずもがな言語には、英語、中国語、日本語など様々なものがあり、それぞれが異なる文法、単語、文字を併せ持ちます。ACLでは、今回紹介した離散性や隠れた構造に関する挑戦の他にも、より大局的に複数言語間で学習の結果を共有や転移させようとする試みなど、言語ならではの課題や面白さが詰まった研究が多く発表されています。これらの研究が自然言語処理のみならず、離散記号や系列データを扱うその他の分野でも応用されていく可能性もあると思います。PFNでは、引き続きロボティクス、コンピュータビジョン、音声処理などの多様な分野とともに自然言語処理の研究開発を行っていきます。