Blog
本記事は、2019年インターンシップとして勤務した徐 子健さんによる寄稿です。
2019年度夏季インターンのJoeです。この度インターンプロジェクトとしてCuPyのカーネル融合の拡張に取り組み、既存のカーネル融合の適用範囲を大幅に拡張しました。さらにその応用として、ResNet50のバッチ正規化においてCPU実行時間を30%ほど、GPU実行時間を(入力サイズに大きく依存しますがおおよそ)70%ほど削減することに成功しましたので、その取り組みをご紹介します。
背景
CuPyはNumPyと同じAPIを提供するPythonのライブラリで、CUDAを用いて演算を高速に行います。具体的には、行列・ベクトルの要素ごとの演算や、リダクションと呼ばれる、演算によって配列の次元が落ちる演算(たとえばcupy.sum)など、GPUが得意とする計算を高速に行うことができます。
さて、CuPyのGPU演算は強力ですが、CPUからGPUカーネルを呼び出す際には、GPU内で実際に行われる処理によらずおおよそ10 μsほどのオーバーヘッドがCPU側にかかってしまいます。cupy.addやcupy.mulのような演算が呼ばれるたびにGPUカーネルを呼び出していては、無視できない量のオーバーヘッドが発生してしまいます。
そこで、いくつかの演算を融合したCUDAコードを実行時に動的に生成することにより、GPUカーネルの呼び出しを減らすことによる高速化が重要となります。この技術をカーネル融合といいます。詳しくは後述しますが、要素ごとの演算を組み合わせた関数やリダクション演算を一度まで含む関数に対するカーネル融合は現在のCuPyにもすでに実装されています。
https://docs-cupy.chainer.org/en/v6.4.0/reference/generated/cupy.fuse.html
カーネル融合で行っている処理を具体的に説明するために、以下のPythonで書かれた関数に配列(cupy.ndarray)を引数に与えて実行したときに、カーネル融合をしない場合とする場合に生成されるCUDAコードを比較してみます。
def f(x):
return x + x * x
カーネル融合をしない場合
このとき掛け算と足し算の両方の呼び出しでCUDAコードが生成され、2度のカーネル呼び出しが発生します。
具体的には以下のようなコードが生成され、関数single_op_mulとsingle_op_addがそれぞれ実行されます。
__device__ void mul_element(int &src1, int &src2, int &dst) {
dst = src1 * src2;
}
__global__ void single_op_mul(Array& in, Array& out) {
int a = in[tid], b;
mul_element(a, a, b);
out[tid] = b;
}
__device__ void add_element(int &src1, int &src2, int &dst) {
dst = src1 + src2;
}
__global__ void single_op_add(Array& in1, Array& in2, Array& out) {
int a = in1[tid], b = in2[tid], c;
add_element(a, b, c);
out[tid] = c;
}
カーネル融合をする場合
この場合、2つの演算は1つの関数にまとめられて、以下のように生成される関数fusedが呼ばれ、カーネル呼び出しは1回で済みます。
__device__ void add_element(int &src1, int &src2, int &dst);
__device __ void mul_element(int &src1, int &src2, int &dst);
__global__ void fused(Array& in, Array& out) {
int a = x[tid], b, c;
mul_element(a, a, b);
add_element(a, b, c);
out[tid] = c;
}
このとき、カーネル呼び出しの回数が1回に減るのでCPU時間が短縮されます。さらに、x[tid]部分はグローバルな配列にアクセスしていて、GPU側のボトルネックになりがちですが、処理をまとめることで、こうしたグローバル領域のアクセスの回数を減らすことができ、GPU側の高速化にも繋がります。
要素ごとの演算とリダクション演算のカーネル融合
既存のカーネル融合は要素ごとの演算だけではなく、一度までリダクションを含む関数ならば融合することができます。上述した例に示したような要素ごとの演算を組み合わせた関数に対するカーネル融合は比較的イメージしやすく、生成するCUDAコードもcupy.addやcupy.mulに相当する演算をつなげるだけでいいので簡単ですが、要素ごとの演算とリダクション演算を融合しようとすると話は少しややこしくなります。要素ごとの演算のカーネル融合ではGPUの各スレッドが特定の位置の要素を独立に扱っていましたが、リダクション演算では、各スレッドは適切に同期されながらシェアードメモリに読み書きを行い、演算を処理します。
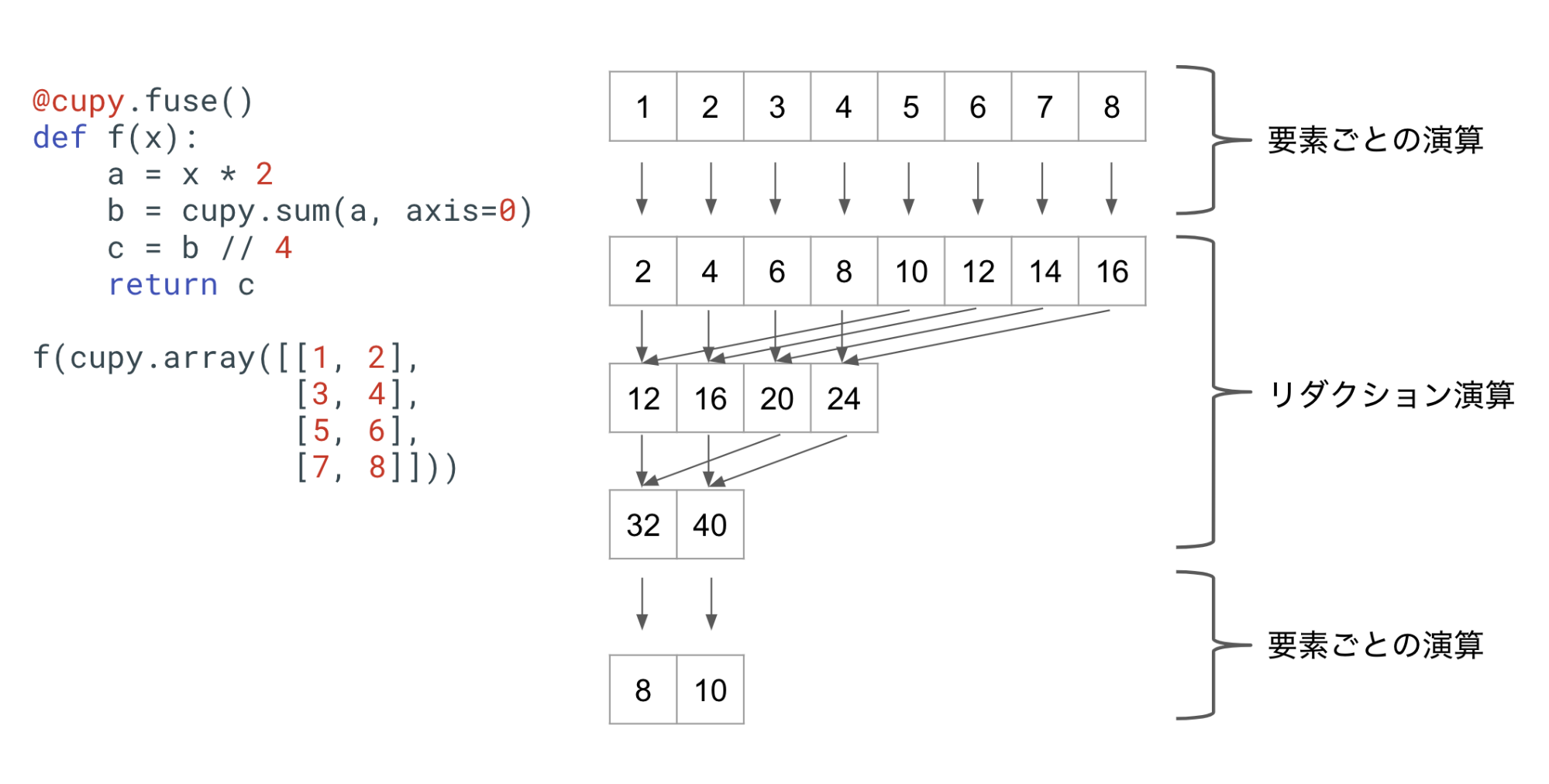
上の図は、既存のカーネル融合で、要素ごとの演算とリダクション演算からなる関数を融合した場合にGPUで行われる処理を表したものです。ここで、リダクション前の演算はすべてリダクションの入力と同じサイズ(正しくは、cupy.ndarrayのshapeのこと。以下同様)をもち、 リダクション後の演算はすべてリダクションの出力と同じサイズをもちます。逆にこのような制約のもとで表せない関数には既存のカーネル融合を適用できません。
このような、リダクションを一度行う関数を融合することは、先程説明したような要素ごとの演算のみからなる関数を融合する場合よりは難しいですが、それでも元のリダクション演算の前後に、要素ごとの演算を織り込むだけで実現することができます。
課題
今回のインターンの課題は、カーネル融合で扱える関数の範囲を広げ、要素ごとの演算とリダクションからなる関数ならなんでも融合できるようにする、というものでした。実際既存のカーネル融合において、リダクションが一度までというのは大きな制約であり、例えば平均や分散の計算を伴うバッチ正規化の関数を融合することはできませんでした。バッチ正規化はResNet50などで何度も実行される関数であり、特にカーネル融合の効果が期待される処理でした。
取り組んだこと
リダクションを二度以上含む関数の融合は、一見リダクションを一度だけ含む関数の融合方法を簡単に拡張するだけで実現できるように思えますが、このニ者の間には大きな違いがあります。というのも、複数回リダクションが行われるとき、一度前のリダクションの結果を一時的にGPUのグローバル領域に格納する必要が生まれます。同じサイズの要素ごとの演算のみだと、各スレッドは配列の特定の要素を見続けるので、演算結果の変数をスレッドのローカル変数に保持しておくことができます(リダクション演算が一度だけの場合、出力用配列にそのまま保存するので問題ありません)。しかし、配列のサイズが演算間で変化するとき、スレッドが担当する要素がずれるため、一度結果をグローバル(スレッド間で共通してアクセスできる位置)に保存してやる必要があるのです。具体的には新たな空の配列をグローバル領域に確保しておき、それを使います。
カーネル融合の処理の流れ
具体的なアルゴリズムを説明する前に、カーネル融合の処理の流れについて整理しておきます。
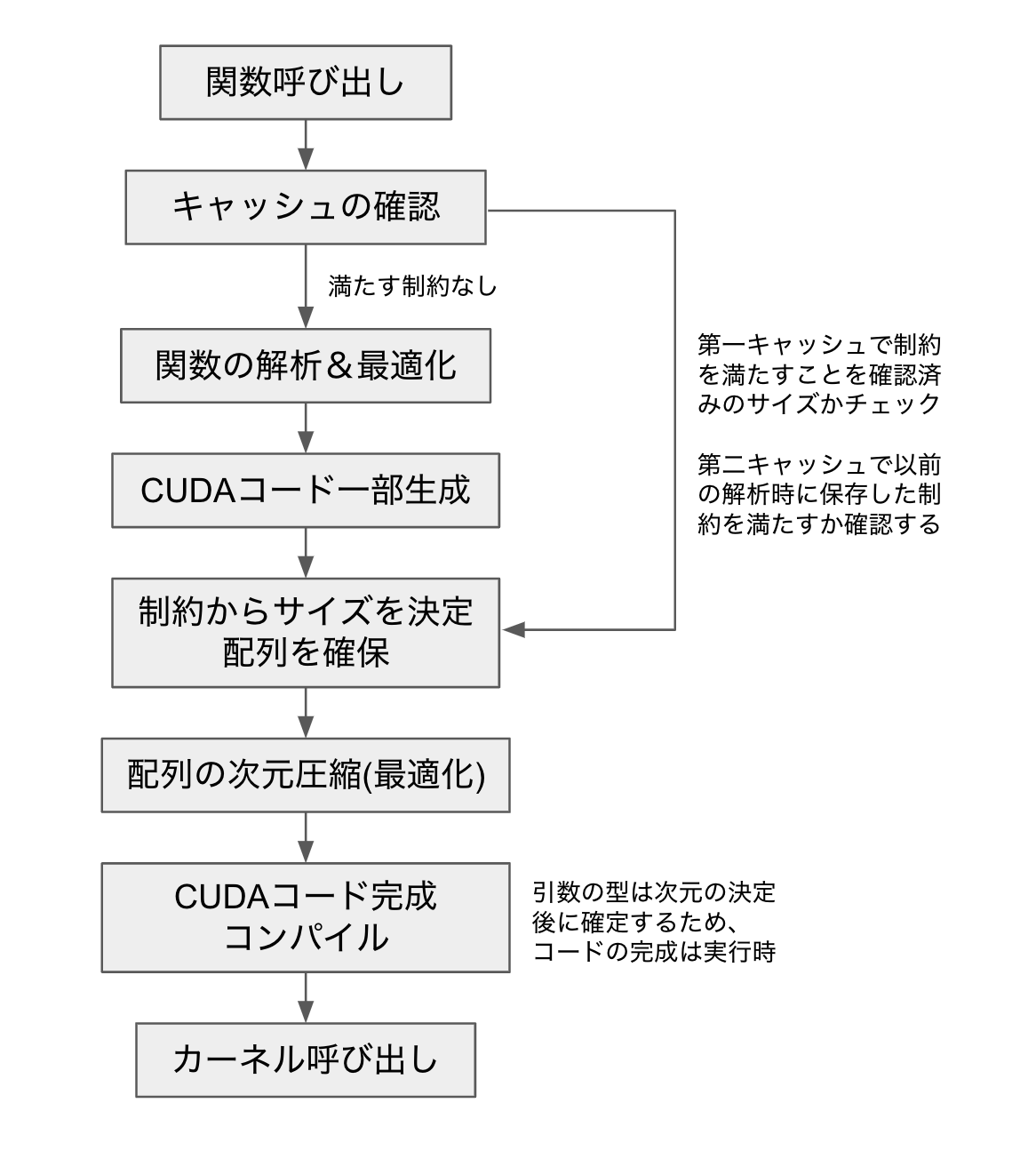
各々の部分の詳細な説明は後述しますが、カーネル融合の処理は大まかに、解析パートと実行時パートに別れます。解析パートでは、CUDAコードを生成するために必要な情報を解析し、CUDAコードの最適化を行います。解析パートは同様な引数の組み合わせに対しては一度だけ実行されることを想定しています。一方、実行時パートは、毎回の関数呼び出しで実行されるパートのことを指します。ここでは、配列の次元圧縮とよばれる実行時最適化を行い、解析パートで得られた情報から実際にCUDAコードを生成し、コンパイルしてカーネルを呼び出します。何度も呼び出されることが想定される関数の場合、関数呼び出しあたりの平均的なCPUの処理時間は、この実行時パートの処理時間にかかっています。それでは、解析パートおよび実行時パートで行っていることを順に説明していきます。
解析パート
サイズの抽象化と制約生成
多段階のリダクションを実現する上で重要なことは、サイズが異なる演算が発生するたびに一時変数をグローバル領域に保存してやることでした。そうした一時変数のメモリを割り当ててやるためには、カーネル呼び出しの直前にサイズを決定してやる必要があります。なぜならば、同一の関数が異なるサイズの入力で繰り返し呼ばれる可能性があるからです。サイズが異なる入力が来るたびにPython関数を解析し直すのは非常に高コストなので、入力の配列のサイズが変わった場合にも同じコードを使えるように変数のサイズ情報を抽象化してを保存したいです。
サイズを抽象化して保存するためには、まず関数の引数で渡される配列のサイズを抽象化して保持します。たとえば、三次元配列xのサイズを(x0, x1, x2)のようにして保持します。これらの抽象化したサイズをもとに、演算を順に追っていき、一時変数の抽象的なサイズを決定します。こうした演算を追う過程で、演算がただしく成立するために必要な、サイズ間の制約が発生します。たとえば、(x0, x1, x2)のサイズの配列と、(y0, y1)のサイズの配列の要素ごとの演算を行うには、後者をブロードキャストする必要があり、このとき、x1, x2, y0およびy1がいずれも1でないとすると、y0 == x1かつy1 == x2がサイズ間の制約となります。これらの制約は関数の解析時に順次保存され、2度目以降の関数呼び出しの際に、与えられた引数のサイズが保存された制約を満たすならば、以前に解析した結果およびコードを使い回すことができます。
CUDAコードの生成
CUDAコードを生成する上での基本的なアイデアは、本稿の初めで説明した、要素ごとの演算のみからなる関数のカーネル融合とほとんど同じです。すなわち、関数内に登場するそれぞれの演算を呼び出し順に記録し、それをつなげて一つのCUDAコードにします。リダクション演算が続いたり、サイズが異なる要素ごとの演算が連続したりするときは、スレッド間で同期をとる必要が生まれますが、基本的にはそれぞれの演算を順につなげたコードを生成すればよいです。
CUDAコードの最適化
さて、ここまでの説明だけだと、カーネル融合が簡単なものに思えるかもしれません。実際、GPUの実行時間を考慮しないならば、演算ごとにサブルーチンを生成し、そのサブルーチンをすべて順につなげればひとつのCUDAコードが完成します。しかし、このままだと本当にGPUを呼び出すための10 μs程度のCPU側の高速化しかなされません。カーネル融合ではCPUのオーバーヘッドをへらすだけではなく、GPUコードの無駄な処理を省くことでGPU側の高速化をも期待することができます。
さて、各演算を順に結合しただけのCUDAコードは無駄な処理を多く含みます。たとえば直前の演算で結果をグローバルな配列に格納し、次の演算でまた同じ要素をグローバルな配列から読み出すのは明らかに無駄です。こうしたケースでは演算結果をスレッドごとのローカル変数に記録してやると大きな高速化に繋がります。
たとえば、愚直に生成したCUDAコード内で以下のような部分があったとします。
tmp[tid] = a;
// ここまで一つの演算に対応。変数aを出力として一時変数に格納
// ここから新しい演算が開始。変数aを新しい入力として一時変数から読み出す
int b = tmp[tid];
このとき、配列tmpが一時変数で、しかもここでしかアクセスされない変数であるならば、
int b = a;
と処理を短縮してやることができます。GPU演算で各スレッドが担当する演算は非常に軽量であることが多いため、このようにグローバル配列へのメモリアクセスを削減してやるだけでも大きな高速化に繋がります。
今回、要素ごとの演算間のみならず、リダクション演算が混じる場合にもこうしたグローバルなメモリアクセスを減らす最適化を行いました。他にもスレッド同期の削減など非常に多様な最適化を試行錯誤し、結果として、従来のカーネル融合を適用できる演算については、ほとんど劣ることがないレベルまでに最適化がなされています。また、高速化とは直接関係ないですが、一時変数の生存解析をすることにより、メモリを共有できる変数はメモリを共有することで、実行時の消費メモリを抑える最適化も実装されています。
実行時パート
配列の次元圧縮
詳細な説明は省きますが、多次元配列の要素にアクセスするとき、一次元配列の要素アクセスよりも時間がかかります。そこで、配列のデータ領域がメモリ上で連続していて低次元配列だとみなせるときに、要素アクセスをより単純に行うための実行時最適化を行います。完全なCUDAコードを生成するためにはこの最適化後の次元を知る必要があるため、完全なコードの生成およびコンパイルは実行時に行われます。CUDAコードのコンパイルはCPU時間に含まれますが、キャッシュされるので一般に高速であり、次元圧縮によるGPU実行時間の削減のほうが効果が大きいため、この方式を採用しています。
実験結果
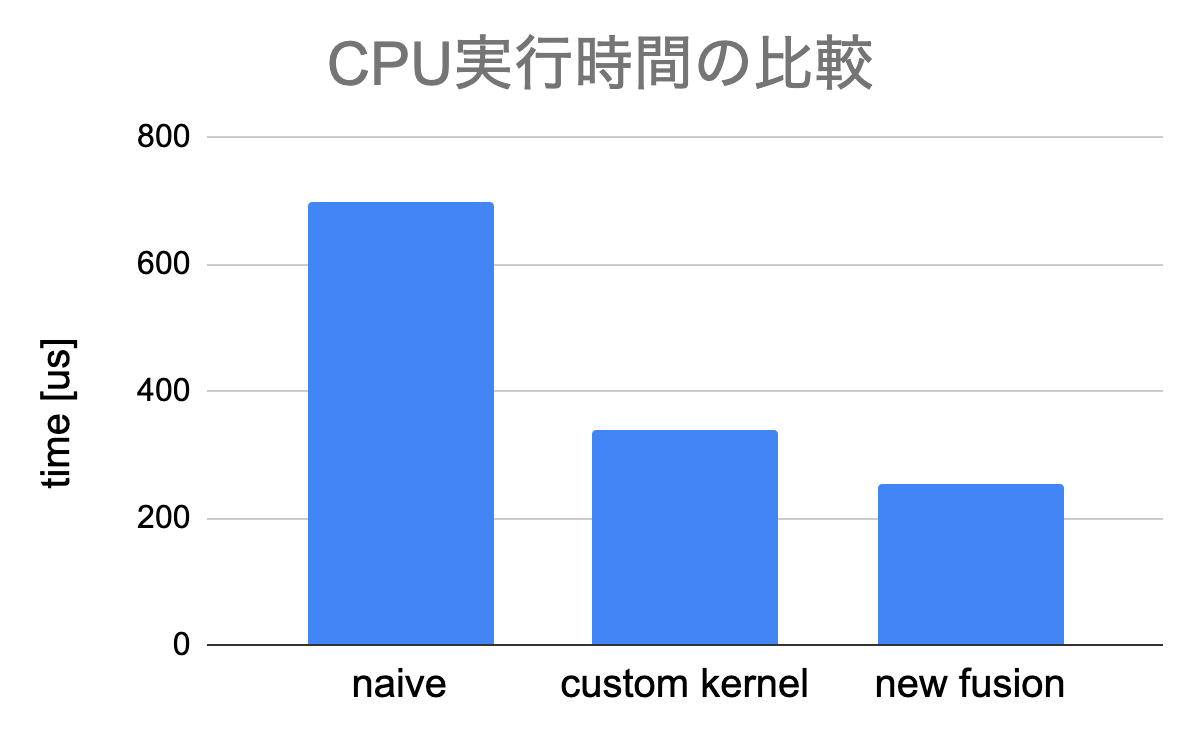
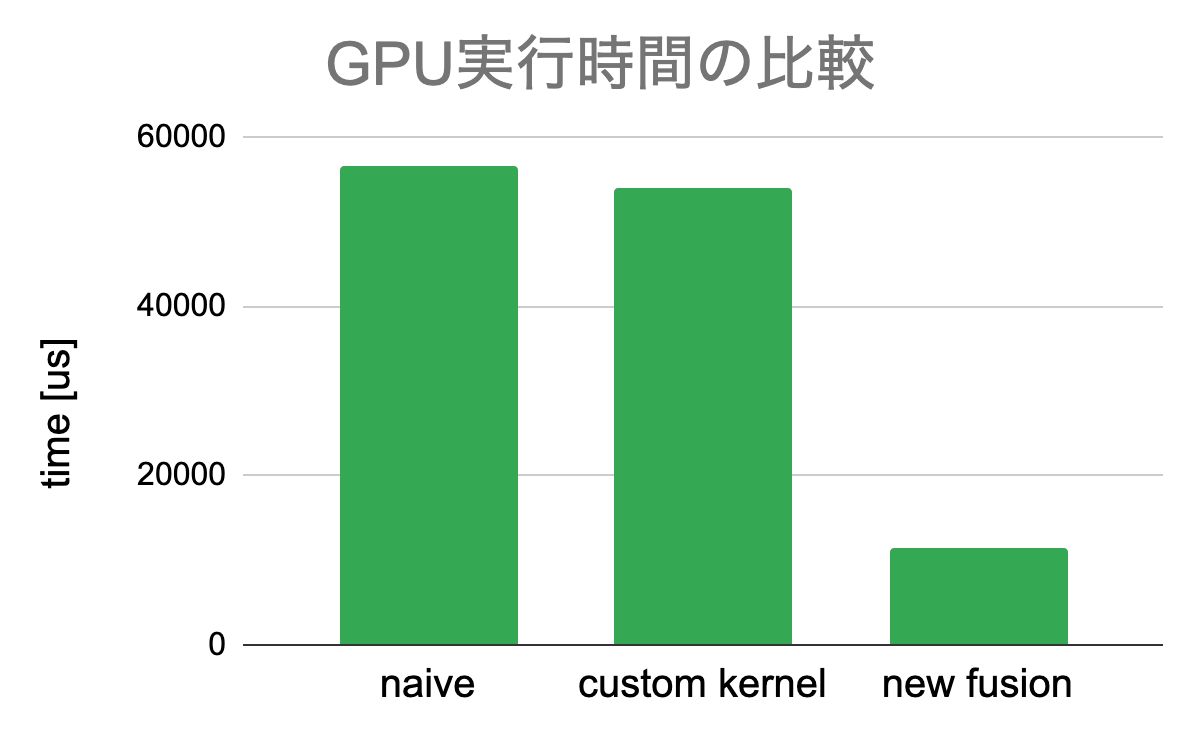
ResNet50のバッチ正規化部分のコードを融合し、CPU時間とGPU時間を比較しました。実験を行った環境は以下のとおりです。CUDA: 10.1, GCC: 5.4.0 GPU: Tesla P100. また、ResNet50でバッチ正規化される配列のサイズは様々ですが、今回はその中の一つである(32,256,56,56)を採用しました。これは縦横56×56の画像を256チャネル分、32枚を正規化する処理に対応し、軸(0,2,3)について正規化をすることで、出力のサイズは(256,)になります。
比較対象は、カーネル融合をせずにそのまま呼び出した場合(naive)と、実際に採用されている実装である、要素ごとの演算部分だけを融合した実装(custom kernel)です。今回実装したカーネル融合(new fusion)はCPU時間、GPU時間の両方の削減に成功しました。
CPU時間は、実行時の配列のサイズに依存せずほぼ一定の割合短縮されました。また、GPU時間についても、従来のボトルネックであった、分散計算時の余分なメモリアクセスを潰すことができたため大幅に短縮されました。
まとめ
今回のインターンでは、既存のカーネル融合を拡張し、複数回のリダクション演算が含まれる場合にも対応し、無事高速化を達成できました。複数回のリダクション演算にも対応させたカーネル融合を実現する上での理論的な大枠はかなりシンプルで、一時変数に多くの情報(もっとも重要なものは抽象的なサイズ情報)を記録させながら演算をたどれば実現できるのですが、そうして生成されたコードは既存のカーネルで生成されるコードに比べ極めて冗長で、最適化を十分に施さない限り高速化が見込めない、という点が大変でした。アルゴリズムの大枠は序盤から見えていましたが、実際にベンチマークを更新したのはインターン終了直前という形になってしまいました。
アプリケーションに新しい機能を追加をする開発と違い、高速化を目指すための機能追加は、高速化を実現できて初めて世に広まるものなので、プロジェクト自体が成功するかどうかはインターン後半までかなり心配していましたが、無事に高速化を実現できてよかったです。
今回のインターンを通して、頼りになるメンター・副メンターとともにこのような挑戦的なプロジェクトに携われてよかったです。
