Blog
エンジニアの吉川です。
先日8/3~8/7にデータサイエンス応用の国際会議KDD 2019が開催され、弊社からも5人のメンバーが参加しました。
このKDD 2019の中でKDD Cup 2019というコンペティションが開かれ、その中のAutoML TrackにPFNのチーム(吉川真史、太田健)も参加し、5位に入賞しましたので、ここで報告したいと思います。
KDD Cup 2019 AutoML Trackについて
KDD Cup は KDDに付随して毎年開かれるデータサイエンスのコンペティションで、最初のコンペが開催されてから20年以上がたちます。昨年までは、通常のデータサイエンスのコンペティション同様に、データが与えられて、参加者が自分の環境で、データを分析し、何らかの予測を行い、その精度を競うというコンペでした。今年からは、それに加え、AutoML TrackとHumanity RL Trackが新設されました。また、AutoML TrackはKDD Cupの一つの部門という位置付けであると同時に、AutoML Challengeという2014年から開催されているコンペティションも兼ねています。
AutoMLはAutomated Machine Learningの略で、機械学習の一部、あるいは全体のプロセスを自動化することを言います。コストを削減したり、機械学習導入の障壁を下げることが期待されていて、KaggleでもAutoMLのベンチマークとしてコンペティションのタスクを提供するなど、最近注目されています。
問題設定
今回のコンペティションでは、参加者がAutoMLの処理を行うコードを提出し、それをコンペが用意した環境で動かし、その性能を競います。
問題設定は、複数テーブルデータに対する2値分類のタスクです。テーブルデータとは、CSVファイル等の形式で表現されているデータ形式で、行列と似たような形で値が格納されています。このテーブルデータが複数あり、データセットに対して1つのメインテーブルが用意されています。このコンペに提出するコードで、メインテーブルのそれぞれの行に対して、何らかの事象が1か0かを確率として予測します。
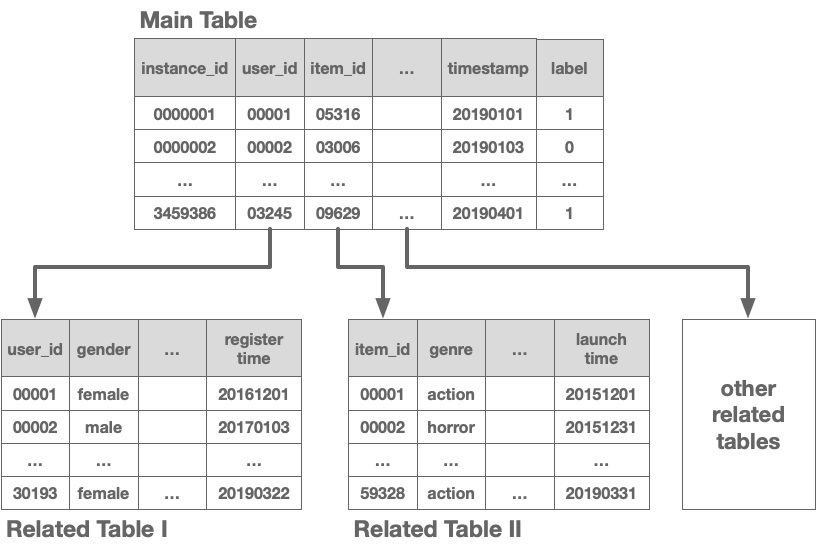
上の例では、メインテーブルのそれぞれの列には、instance_id, user_id等が割り当てられているのですが、それぞれデータの型を持っています。
- numerical: 連続値
- categorical: 離散値(上の例だとidや、gender等)
- time: 時間
- multi categorical: 任意の長さのcategoricalデータの列(例えば、自然言語で書かれた文で単語のIDを並べたものなど)
また、計算リソースに対する制約もあり、
- 時間制限
- CPUの数
- メモリの大きさ
それぞれに対して、うまく対処する必要がありました。
今回のコンペの傾向
今回のコンペでは、161チームが参加しました。順位変動が大きいコンペティションになっていたと思います。データセットとして、公開されているpublicのデータセットと、公開されていないprivateのデータセットが用意されました。開催期間中はpublicの順位が表示されているのですが、最終的な結果はprivateで判断されます。publicのみで高い性能を出すコードを提出した場合、順位が落ちてしまうということが起こります。
また、エラーに関してシビアなコンペになりました。最終的な評価の時にprivateデータを使うため、仮にpublicでエラーなく動いたとしても、privateでエラーが出てしまった場合に、評価ができません。このコンペでは、1回エラーが出た場合に再提出が許されましたが、2回目のエラーは許されないというルールでした。実際我々のチームでも1回目はTimeout Errorが出てしまいました。
これらのことがあり、publicで入賞圏内にいた10チームのうち5チームのみが最終的に入賞することになりました。
入賞したチームのほとんどが、前処理 -> 特徴量エンジニアリング -> ハイパーパラメーター調整 -> モデリングと言うパイプラインで行っていて、そのそれぞれを工夫するということをしていました。 機械学習モデルとしては全入賞チームがLightGBMを使っていました。
我々の開発方法
まず、開発・検証環境を整えました。ただし、基本的には性能検証のコードや環境のDocker imageは運営で用意されていましたので、それをほとんど使いました。データに関しては、publicのデータセットについてはラベルが用意されていなかったので、trainデータを時間で分割するという方法で、検証用のデータを用意しました。これにより提出することなしに、自分の環境で検証が回せるようになりました。
今回、検証の時に課題に感じたのが、複数データセットに対して、いかに汎用性の確度の大きく、高速に検証を回すようにできるかということです。全てのデータセットに対して、検証を行うと、時間がかかってしまいます。かと言って一つのデータセットだけを回すと汎用性の低いものができてしまうと思います。自分は今回は、複数データセットをその都度選んで検証するという方法をとりましたが、やっていくうちに、あるデータセットだけに偏って検証してしまうということがあり、最終的なモデルの汎化性能に影響が出てしまった可能性があります。
我々のソリューション
実際に発表に使ったソリューションのポスターが以下になります。

一番工夫したところは、特徴量エンジニアリングをするところです。特徴量エンジニアリングは、機械学習が予測しやすいように、特徴量を作ることを言います。自動特徴量エンジニアリングの研究というのはいくつかなされていて(Deep Feature Synthesis[1], One Button Machine[2])、ルールベースに特徴量を作ってしまうという方法がベースになっています。
我々の手法でも、同様のアプローチをとりましたが、ルールベースで全ての特徴量を合成してしまうと、とてもリソースを消費してしまったり過学習の要因になり得ます。そこで、事前に特徴量を選ぶということを行いました。
- 実際に特徴量自体を計算せずに、どういう特徴量がありうるかを列挙する
- それぞれの特徴量のメタ特徴量(どういう特徴量かということをベクトルとして表現したもの)を計算する。
- そのメタ特徴量をある関数に通すことで優先度を計算する。
これをすることで、重要な順番に特徴量を合成することができ、メモリや時間を使いすぎていたら途中でやめることができます。実際これによって順位が大幅に上がりました。
ここで優先度を計算する関数ですが、これをメタ学習により作りました。
- 他のデータを使って特徴量を全てあらかじめ計算しておき、Permutation Importance(特徴量の重要度を計算する方法の一つ)を計算する。
- それをメタ特徴量から線形回帰する。
このようなメタ学習をすることにより、他のデータセットで得られた知見を適用することで良い優先度づけができることを期待しました。
またハイパーパラメーター最適化では、ハイパーパラメーター最適化ツールであるOptunaを使用しました。ハイパーパラメーター最適化では、ハイパーパラメータを変えて実際に何回か学習を回します。そのため、時間がかかってしまい、いかにそれを短くするかというところが重要です。今回は、Pruning(枝刈り)というテクニックを効率化するために使いました。Successive Halving AlgorithmというPruningのアルゴリズムがOptunaに実装されていて、それを使用しました。
1stソリューション
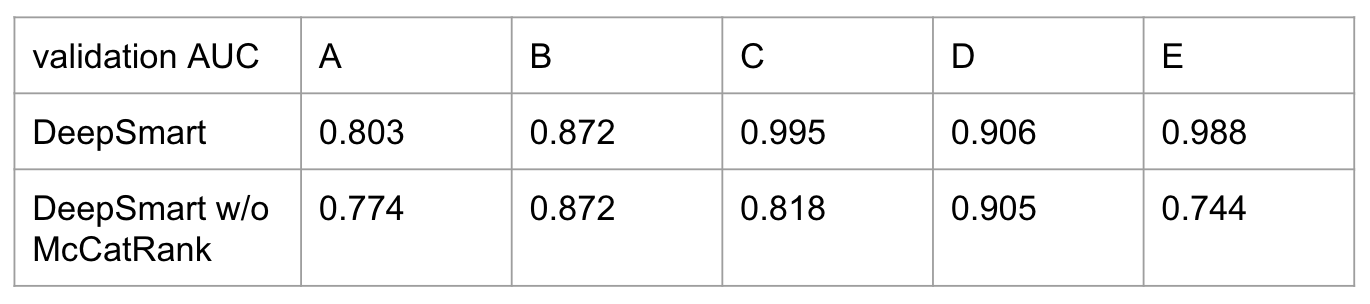
今回のコンペでは、1位のチーム(DeepSmart)が2位以下に大きな差をつけていました。データセットによっては、他のチームが0.7や0.8というAUCの中、AUC=0.99というスコアを出していました。1位のチームも大枠の前処理 -> 特徴量エンジニアリング -> ハイパーパラメーター調整 -> モデリングというパイプラインは同じであり、KDD 2019での発表を聞いても、どこでそこまで大きな差がついたかわかりませんでした。そこで、実際にpublicのデータで調査を行いました。
結論から言うと、McCatRankという特徴量が決定打でした。1位のソリューションから、そのまま動かした場合と、McCatRankに関する部分を除いで動かした場合の結果が以下のようになります。特にデータセットCとデータセットEで差が出ていることがわかります。
このMcCatRankという特徴量は、下の図のように、Multi CategoricalのデータとCategoricalのデータを取ってきて、Multi Categoricalの中でCategoricalがなかった場合に0を、あった場合に何番目にあるかと言う値を特徴量としたものです。

試しに、データセットEから、あるMulti CategoricalデータとあるCategoricalデータを取ってきて、McCatRankの特徴量を作りました。このデータセットの場合では、特にMcCatRankが0かどうか(つまりCategoricalの値がMulti Categoricalの中にあるかどうか)が、ラベルと相関があって、以下の表にような集計が得られました。実際にこの特徴量単体でAUC=0.951となり、McCatRankを使わずに学習した場合の性能を上回っていました。

また、このチームのコードでは、ハイパーパラメーター最適化では、hyperopt,Optunaなどのツールを使っておらず、データサイズ、特徴量の数などから、ルールベースに決めたり、全探索的に探索したりして、そのルールを試行錯誤していたようでした。実際に今回の問題設定では、ブラックボックス最適化アルゴリズムをそのまま適用するよりも、人間の経験に基づいて最適化の方法を決めた方がよかったのかもしれません。
最後に
今回のコンペでは、AutoMLに関する知見を得ることができ、とても有意義なものになりました。他チームのソリューションからは、自分が思いついていなかったアプローチが多くあり、学ぶことがありました。
PFNではAutoMLに関して社会実装に向けた、Optunaを中心とした技術開発を進めていきたいと考えています。
文献
[1] Kanter, James Max, and Kalyan Veeramachaneni. “Deep feature synthesis: Towards automating data science endeavors.” 2015 IEEE International Conference on Data Science and Advanced Analytics (DSAA). IEEE, 2015.
[2] Lam, Hoang Thanh, et al. “One button machine for automating feature engineering in relational databases.” arXiv preprint arXiv:1706.00327 (2017).
