Blog
こんにちは。コロンビア大学の久米です。7月からの2ヶ月間、ロボットと機械学習をテーマにインターンをしました。この記事は先日、ustreamで発表した内容のダイジェスト版となっています。
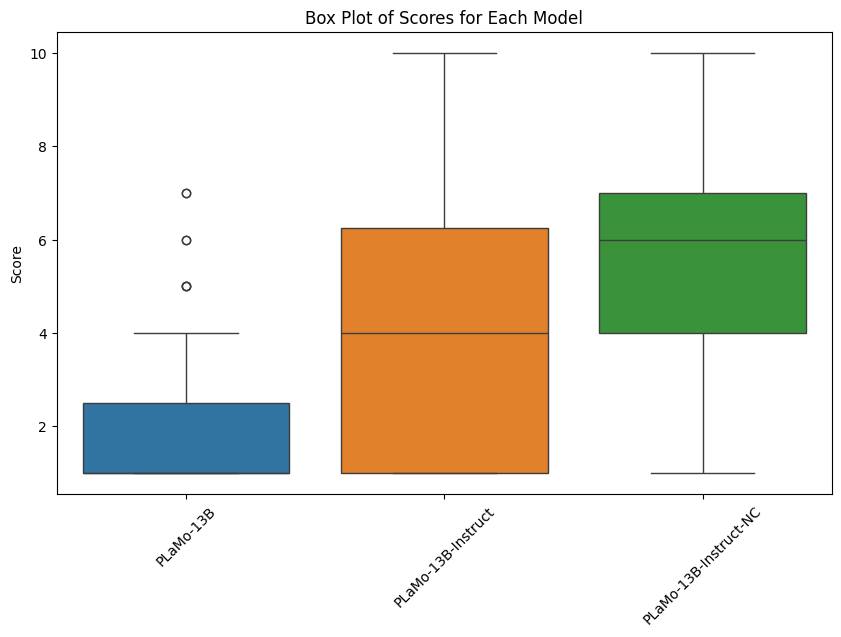
インターンでは、6本脚ロボットが脚を失ってもすぐに新しい歩き方を学習する方法の実装を行いました。具体的にいうと、Natureで2015年に発表された、Robots that can adapt like animals(PDF)の再現実験です。ロボットの組み立て、シミュレーション(事前学習)、手法の実装、実験をしました。
下の動画を御覧ください。6本脚ロボットは、6本の脚を使って歩行します。左側の動きが通常時の動き方です。歩行中、脚を一部失ってしまうこともありえます(下の写真)。そうすると右側の動画のように同じように脚を動かすだけでは、前向きに歩くことができなくなってしまいます。
今までの方法では、ロボットが脚を損失した状態で前進する歩き方を見つけるためには、事前に色々な状況に対して歩き方を設定しておくか、学習するとすればたくさんの時間がかかっていました(強化学習など)。
提案手法では、脚がなくなってしまっても数回から数十回程度の試行で前進する方法を発見することができます。下の方に結果を掲載していますが、実際に実験してみると、1本脚の先がなくなったり、2本の脚が動かなくなっても、5種類の歩き方を試しただけで前進の方法を発見しました。
手法のコンセプトは次のような感じです。
まずは、健康な状態の時に色々な歩き方を試しておきます(事前学習)。上手く前進できなくなった時には、事前に覚えていた歩き方の中からいくつか試して、良い方法を発見します(Adaption step)。
事前学習
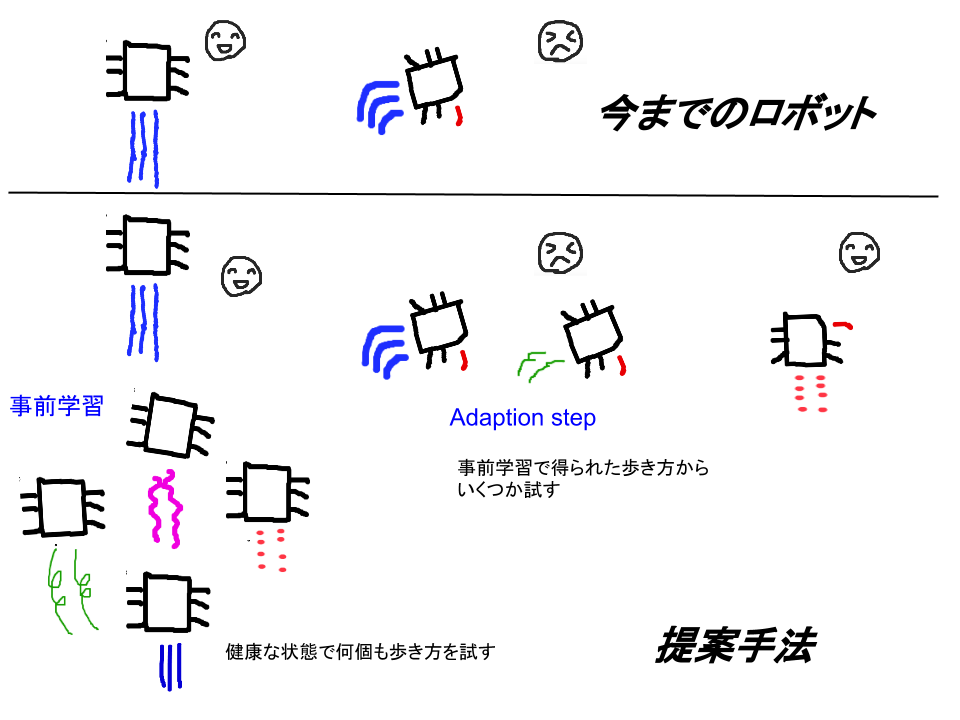
実際の歩き方は36個のパラメーターを指定して決定するので、歩き方は膨大に存在します。
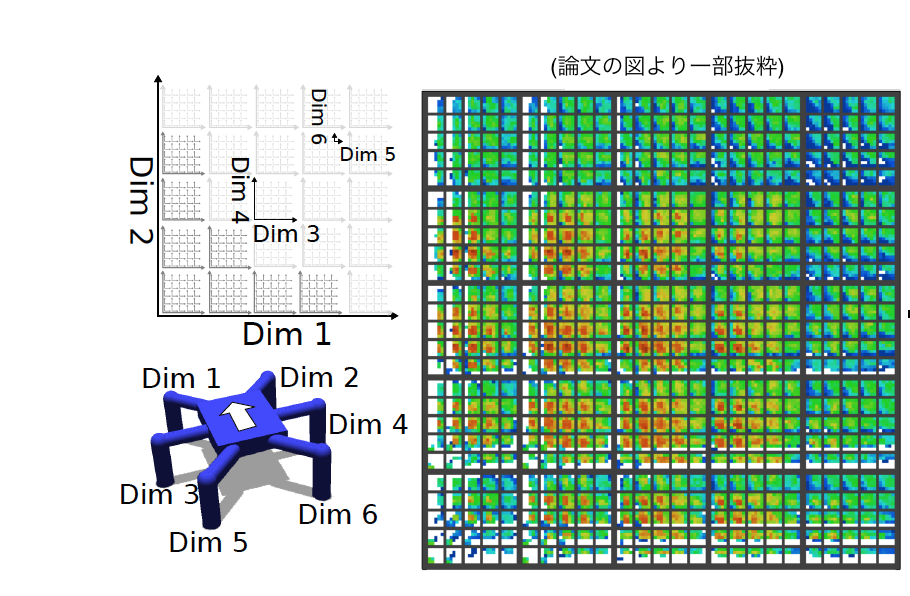
色々な状況に対処するためには、ただ良い歩き方を記憶するだけではなく、色々な状況に対して良い歩き方を記憶する必要があります。論文では「各脚の着地時間」をその指標にし、パフォーマンスのマップを作成しています。つまり、各脚の着地時間という6次元の値に対して、着地時間も5通りに離散化して、各脚0%,25%,50%,75%,100%に分類し、合計で15625通りの状況を想定します。
下の図が、このマップを2次元に表したもので、脚1と2の着地時間によって、大きい四角形の場所が決まり(左下ほど着地時間が少ない)、3と4の着地時間によって、各大きい四角形の中の小さな四角形の場所を決定、5と6については小さい四角形の中の場所を決定します。
各脚の着地時間に応じて場所が決定し、そこにパフォーマンスとパラメーターを記憶していきます。
事前学習のやり方
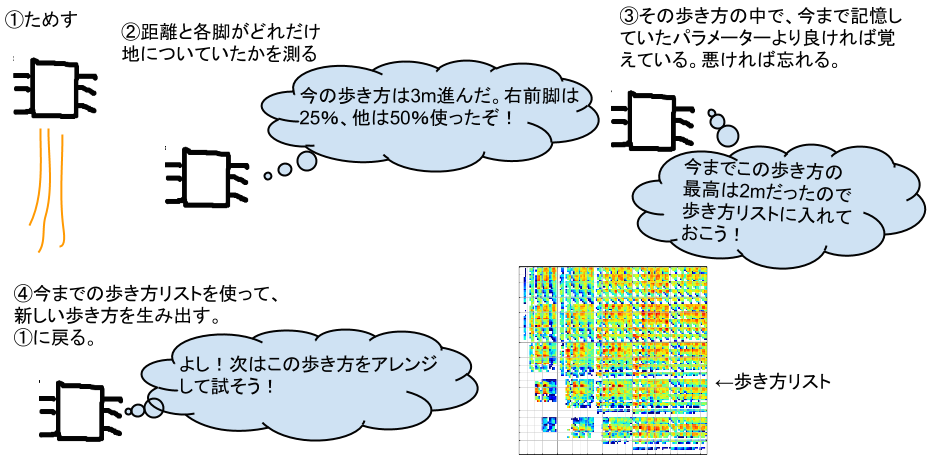
- 一つの歩き方を試す
- 歩き方の距離(パフォーマンス)と各脚の着地時間(状況)について計測する
- その状況の距離が今まで記録されていなければマップに記録する。記録されていても、今回の方がパフォーマンスが良ければ記録を上書き、悪ければこの歩き方は捨てる
- 今までに記録されている歩き方を少し変化させて歩き方を試す(上に戻る)
何千万回もの試行が必要なため、事前学習は実機ではなくシミュレーション上で行います。
事前学習の結果
シミュレーションは、Open Dynamics Engine(ODE)という物理シミュレーターを使って行いました。
私は実際に 5188万4543回のシミュレーションを行って、マップを作成していきました。
Amazon AWSを使って並列実行し、10日間位で学習しました。
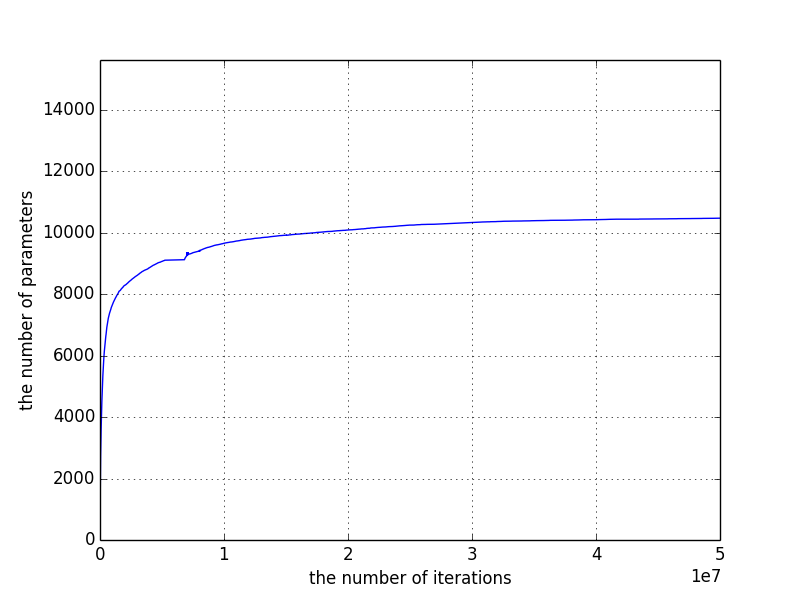
この図は、横軸がシミュレーション回数で、縦軸がマップの中で埋まったマスの個数です。
仮に全部埋まったとしたら15625マスですが、新しいパラメーターを既存のパラメーターから作っていくことと、動きようがない部分(0,0,0,0,0,0)なども存在するので全部は埋まりません。

これらが、マップの途中経過です。回数の下の数字は最大値と平均値です。図は、最終マップの最大値を1(赤)とした時のそれぞれのマスのパフォーマンスを示しています。初めの1000万回くらいで、マップのマスの数自体は増えなくなりますが、パフォーマンスは向上しているのがわかります。
Adaption step
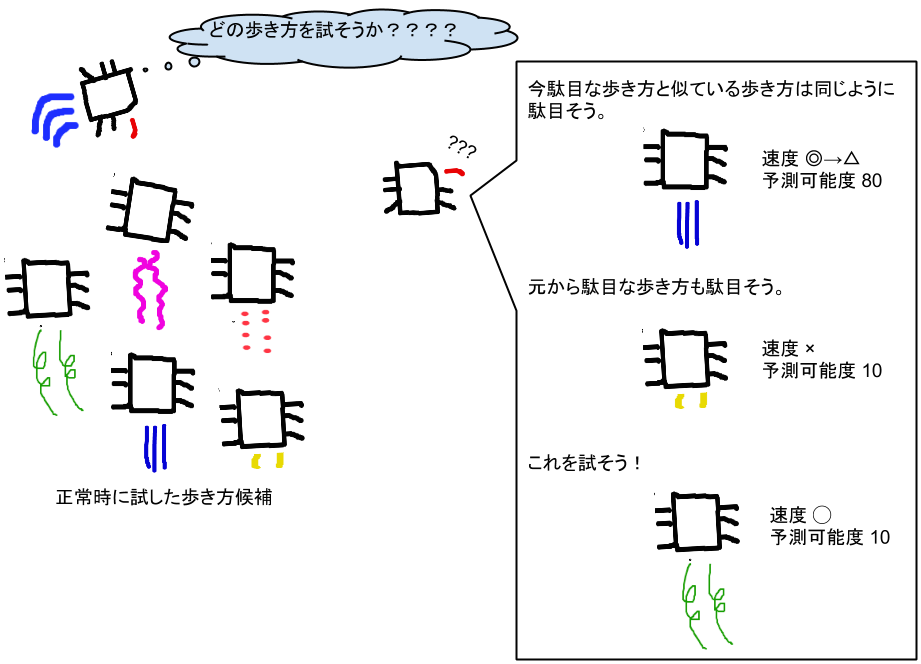
実際にロボットが壊れてしまった時には、マップの中から新しい歩き方を試します。
その時には、今歩いている方法はあまり良くないので、それに似た歩き方を避けて、かつパフォーマンスが高そうな歩き方を探していきます。
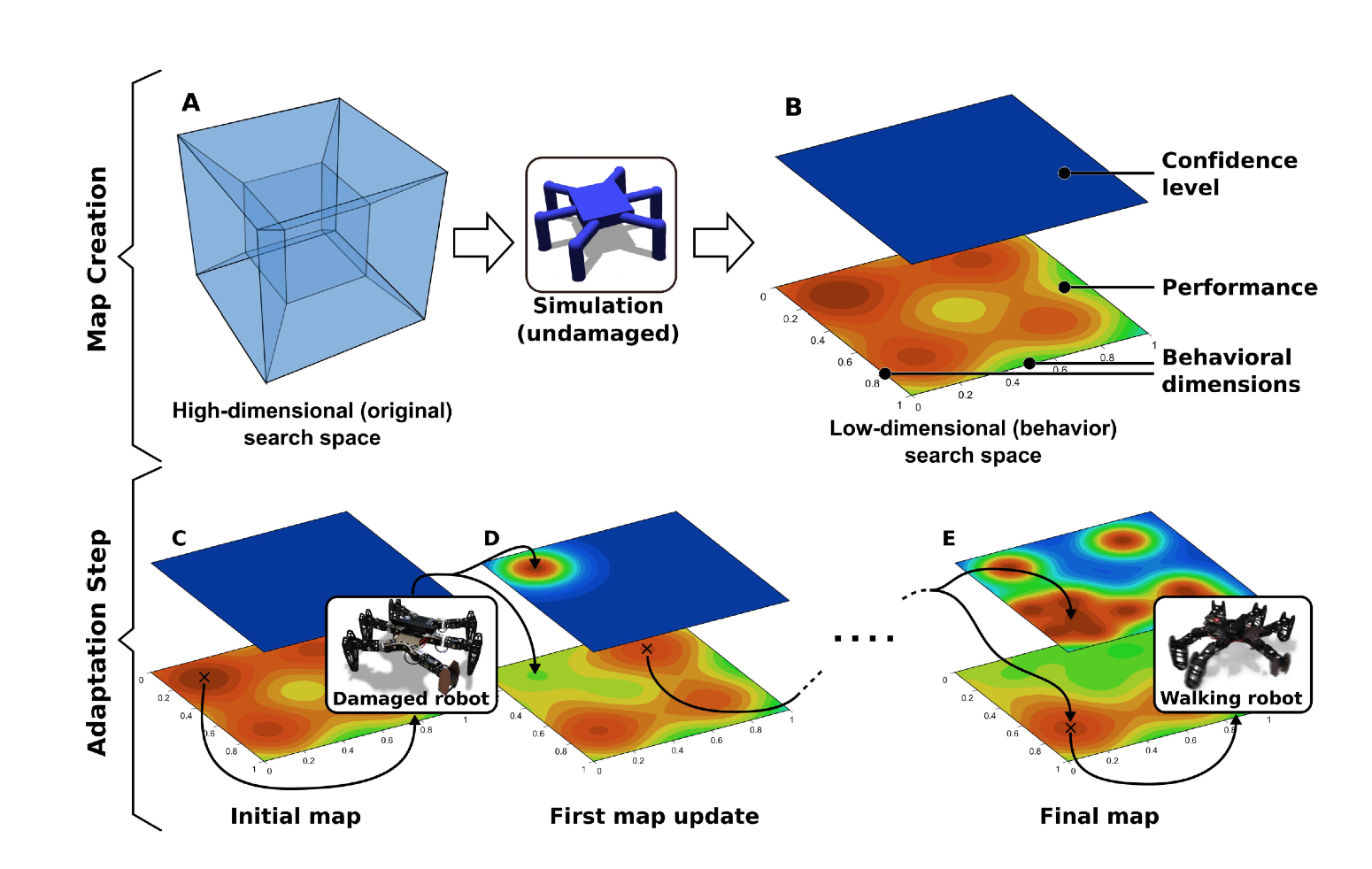
(論文より引用)
初めは壊れたロボットでの歩き方については、実際には試していないため確信度は全て最低レベルで、パフォーマンスは事前学習の時の値です。
一度実際に歩くと、マップ上で既に観測された歩き方に近い歩き方は、確信度が高くなっていき、それと同時にパフォーマンスも観測された値に応じて更新されていきます。マップの更新にはBaysian optimizationを使います。
実験結果
最後に、実験結果の動画です。
動画の見方
脚(6個の数字): 動画の歩き方において各脚がマップの中のどこにいるかを示しています。
各脚0-4までの数字。(着地時間 0%:0 25%:1 50%:2 75%:3 100%:4)
パフォーマンス:計測した値
期待MAX:更新されたパフォーマンスマップでの最高値
パフォーマンスマップの1.0は事前学習での最高値(0.17)。
色々な歩き方を試すうちにマップがどんどん下方修正されていきます。
確信度は青ほど低く、実測されると赤色になっていきます。
最後の方にでてくる相対的パフォーマンスマップというのが、ロボットがその時に持っているパフォーマンスマップの最大値を1としたときのパフォーマンスマップです。
このように、わずか数回の試行で、前進方法を学習することができました!2つ目の実験のように、実際には1回目で良い歩き方を発見した場合でもまずは、もっと良い歩き方がないか探します。調べているうちに全体のパフォーマンスが更新されていって、期待されるパフォーマンスが下がってきて、一回目の歩き方が良い歩き方だということが発覚します。
事前学習のシミュレーションの精度はどうしても完璧というわけにもいかないのですが、それでもこのように成果がでました。
この手法を用いれば、状況が変わった時に、改めて学習をするのではなく、理想的な状況(シミュレーション)にたいして学習を行えば、すぐに色々な状況に対処できるため、常に人間の監視下にいるわけではないロボットに対して応用できれば、突然の事故などに対応できると思います。