Blog
Deep Neural Networkを使って画像を好きな画風に変換できるプログラムをChainerで実装し、公開しました。
https://github.com/mattya/chainer-gogh
こんにちは、PFNリサーチャーの松元です。ブログの1行目はbotに持って行かれやすいので、3行目で挨拶してみました。
今回実装したのは”A Neural Algorithm of Artistic Style”(元論文)というアルゴリズムです。生成される画像の美しさと、画像認識のタスクで予め訓練したニューラルネットをそのまま流用できるというお手軽さから、世界中で話題になっています。このアルゴリズムの仕組みなどを説明したいと思います。
概要
2枚の画像を入力します。片方を「コンテンツ画像」、もう片方を「スタイル画像」としましょう。

このプログラムは、コンテンツ画像に書かれた物体の配置をそのままに、画風をスタイル画像に変換した画像を生成します。

いろいろな例を見てみましょう。コンテンツ画像は先ほどの猫の画像で、左がスタイル画像、右が生成された画像になります。


美術作品をスタイル画像とすると、その画風をかなり良く再現してくれます。色合いだけでなく、小さめの空間パターンまで似せて生成されます。ここには載せないですが漫画作品やゲーム画面なども面白い結果を生み出してくれます。

スタイル画像は絵である必要はありません。美しく生成するのは難しいですが…
他にも寄木細工のような工芸品や、ロマネスコブロッコリーのようなフラクタル系の画像もスタイル画像として優秀でした。

正直ここまでできるとは思ってなかったのですが、新聞や設計図のような画像でも、そのスタイルを抽出することができました。特に、新聞の文字もどきを塗りに使っているところや、設計図のカクカクした感じが猫の輪郭に当てはまっているのには感動です。
元論文や、こちらのサイトなどにも面白いサンプルが多数掲載されているので、もっと見たい方はご覧になってみてください。また、これらの例は全部上のリンクのchainer-goghで生成できるので、興味のある方はぜひ自分で作ってみてください。
アルゴリズムの解説
モデル
このアルゴリズムはCNN(convolutional neural network)を使って画像を生成します。
このCNNとしては予め物体認識で訓練したニューラルネットを使用し、これ以上の学習は行いません。
caffeのmodel zooにILSVRCなどの画像認識ベンチマークで好成績を収めた学習済みモデルが多数公開されており、それを使います。Chainerはこれらのcaffemodelを読み込むことができるのです。
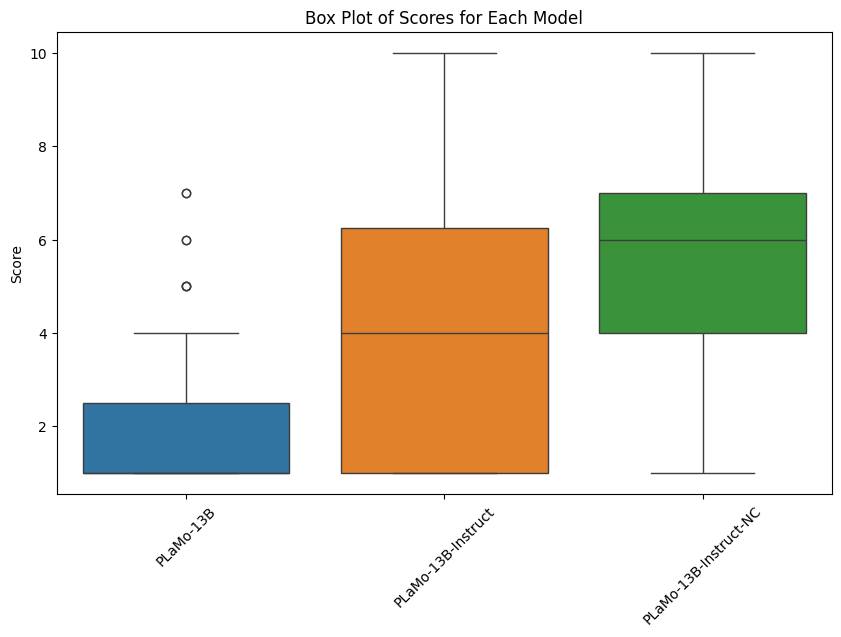
上でお見せした生成例は、VGG 16-layerのCNNモデルを使用しています。これは、次のような構造になっています(後半のFC層などは省略)。
書かれている数字は[チャネル数*縦*横]を意味します。入力画像はRGBの三色なのでチャネル数が3ですが、層が進むとチャネル数が増えていきます。縦横解像度はこの図は256*256を例にしましたが、変えても動作します。
本アルゴリズムでは中間層である①〜④からの出力を使用します。
CNNの中間層
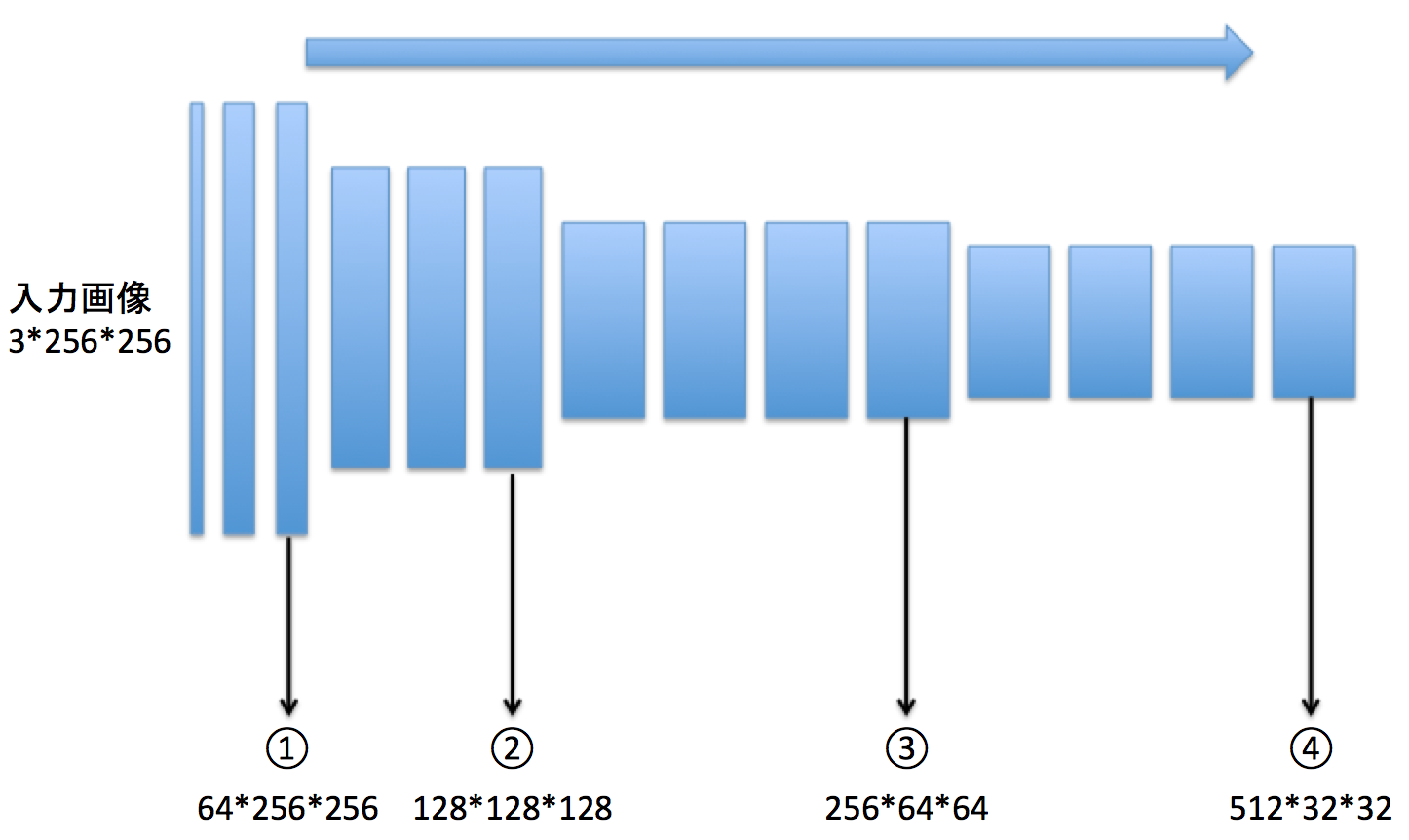
猫の画像をこのCNNに入力し、中間層の出力を可視化すると次のようになります。

①~④は、上のVGGの図と対応します。中間層はもっとチャネル数が多いですが、その中から3つのチャネルの画像を選び出して描いています。
CNNの場合、深い層まで進んでも空間的な位置関係は保たれる(④の場所でもかろうじて猫にみえる)ことは重要です。④で左上の方にある出力は、入力画像でも左上の方の特徴を表しています。これは、CNNが画像のローカルなフィルタ操作を繰り返しかけていることに起因する特徴です。
Deep Neural Networkは層が進むにつれて、タスクにとって重要な特徴量を強調するように情報処理が進んでいくと言われています。
そのことを④の512*32*32のデータのみを使って入力を復元することで、調べてみます。

この絵から分かるのは、まず、CNNを10層以上進んでも、元画像のかなりの情報が残っているということです。一方で、色合いや質感は、元画像から少し変わっています。このことは、もともとこのCNNが物体認識のタスク用で、多少色合いや質感が変わっても物体は同じ物体とみなしてほしいため、その情報を、形などの情報と比較して相対的に弱めているからと考えられます。
本研究のアイデアは、この情報が弱まっている部分を、別の画像の画風に置き換えてやれば、コンテンツ画像の形状を保ったまま別の画風に画像を変換できるのではないか、ということになります。
スタイル行列
画風の情報を表現するために、スタイル行列という概念を導入します。これがこの論文の一番のポイントです。
この行列は、同じ中間層の各チャネル間の相関を計算したものです。入力画像で言えば、チャネルはRGBの各色に対応するので、赤と緑の相関など、つまり「画像全体でどんな色が使われているか」という情報を表すことになります。もう少し層が進めば、「どれくらいの太さの線で書かれているか」といった情報を取り出すことが出来、より深い層で統計すると「どの色とどの色が隣り合って描かれやすいか」「どのようなテクスチャが使われているか」といった情報が反映されると考えられます。
猫画像における、VGGの①〜④の各中間層でスタイル行列を計算したものを可視化すると、以下のようになります。

この行列の2行3列目は、チャネル2とチャネル3の相関をとったものになります。
ここに、色合い、筆のタッチなどの画風情報が埋め込まれることになります。
目的関数
中間層④の出力をコンテンツ画像と同じようにしつつ、スタイル行列はスタイル画像と似せてやることで、ゴッホ風猫画像を生成できると考えられます。
すなわち、このアルゴリズムで最小化したい目的関数は、
中間層のコンテンツ画像とのズレ + スタイル行列のスタイル画像とのズレ
という形になります。
前者のコンテンツ画像とのズレは、物体のおおまかな配置や形状が合うようにしたいので、抽象的な情報が抽出されてる深い層で値の差を測ります。ここを浅い層で差をとってしまうと、ピクセル単位の細かいズレに鋭敏になってしまい、大胆な画風の変更が出来なくなってしまいます。
後者のスタイル画像とのズレは、浅い層でも深い層でも差を測ります。細かい筆のタッチのような情報は浅い層で、大きめの空間パターンは深い層で取り出すという狙いです。
画像の更新則
目的関数が定まったので、あとは確率勾配降下法などで最適化を行います。
画像をCNNに通して中間層を求める処理、中間層の相関を計算する処理、コンテンツ画像・スタイル画像とのズレを計算する処理はすべてChainerのFunctionで書かれているので、backward()を呼び出すだけで各パラメタを動かすべき方向を計算できます。
一般のニューラルネットの学習と異なるのは、動かすパラメタがニューラルネットの結合荷重ではなく、入力画像の方だということです。今回のアルゴリズムではニューラルネットは固定されています。
入力画像はまず乱数で作ったノイズ画像からはじめて、backwardで計算した勾配を利用して最適化していきます。chainer-goghでは、ニューラルネットの学習によく用いられるAdamを使って最適化しています。この部分も、ChainerのOptimizer機能を使えば、update()を呼ぶだけでパラメタの更新をやってくれます。

画像が生成されていく様子を動画にしてみました。まずスタイル画像の模様を全体に描いて、それを少しずつコンテンツ画像にマッチするように変化させていくという描画方法をするようです。おそらく、スタイル画像とのズレのほうが浅い層から誤差が伝搬してくるので、先に最適化されるのだと考えられます。
結果の分析
さて、本当にこのゴッホ猫が、中間層出力がコンテンツ画像と似つつ、スタイル行列はスタイル画像と似ている、という状態になっているのかを確認してみましょう。
まず、猫画像の中間層出力とスタイル行列を再掲します。

次に、ゴッホ画像です。
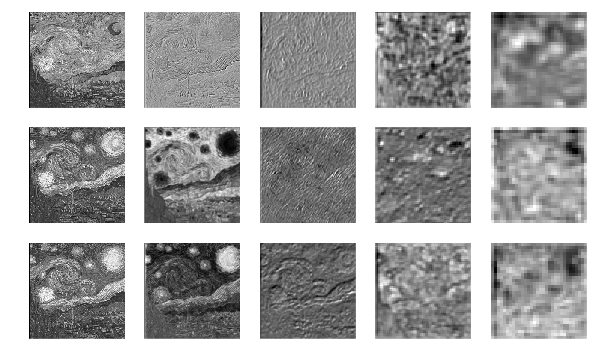

最後に生成したゴッホ猫です。


ちょっとわかりづらいですが、中間層④の出力は、ゴッホよりも猫に近いこと、そしてスタイル行列は①〜④まですべてゴッホの方に近いことが確認できます。こうして、形状をコンテンツ画像から、画風をスタイル画像から受け継いだ画像が誕生したわけです。
おわりに
画像の自動生成は、Deep Learning研究者の一つの夢であり、多くの研究者が研究しているテーマです。
現在成功しているアプローチは大きく分けて2つあります。
まず1つ目は、オートエンコーダー(画像を低次元のベクトルに符号化するNNと、符号から画像に戻す復号NNを両方同時に学習する)を使う方法で、訓練データの画像が符号の空間で正規分布のようなきれいな分布をしていれば、逆に符号側を正規分布からサンプルし、それを復号NNで画像化してあげれば、それっぽい画像が生成されるだろうという発想です。VAEやAdversarial networkを使った研究が有名ですが、このアプローチは”もやっと”した画像が生成される事が多く、手書き数字や顔画像の生成はうまくいっているものの、より大きく複雑な画像生成はそれほど成功していません。

Adversarial networkで生成した自動車、動物、船
2つ目のアプローチは画像を反復的に改良していく方針で、物体認識NNが「犬」と判断するような方向に入力画像の方を動かしていけば犬の画像が描けるだろうという発想になります。ちょっと前に流行ったDeep Dreamがこれにあたります。
しかし、あれは”もやっと”はしていなくても、グロテスクな画像を生成してしまう傾向にありました(まだ見たことない人はDeep Dreamで検索してみましょう)。これは、自然な画像とは似ても似つかなくても、物体認識NNを騙せてしまうことに原因が有ります。
今回紹介した研究は2つ目のアプローチですが、Deep Learningを使って”もやっと”もグロくもない画像を生成することができます。もちろんコンテンツ画像とスタイル画像を入力に必要としているので全自動ではないのですが、コンテンツ画像は深い層の出力のみ、スタイル画像はスタイル行列のみしか情報を使っていないので、画像の完全自動生成に一歩近づいたと言えるのではないでしょうか。今後の発展に要注目です。
Area