Blog
Chainer にマルチノードでの分散学習機能を追加するパッケージ ChainerMN のベータ版を公開しました。
ChainerMN とは
ChainerMN は Chainer の追加パッケージで、Chainer を用いた学習を分散処理により高速化できます。柔軟で直感的に利用できる Chainer の利便性をそのままに、学習時間を大幅に短縮できます。1 ノード内の複数の GPU を活用することも、複数のノードを活用することもできます。既存の学習コードから数行の変更で ChainerMN を利用可能です。ChainerMN は既に社内の複数のプロジェクトで実証が行われています。
Chainer を用いた通常の学習における 1 イテレーションは下図のように Forward, Backward, Optimize の 3 つのステップからなります。

ChainerMN はこれに、下図のように、通信を行う All-Reduce のステップを挿入します。All-Reduce のステップでは通信を行い、全ワーカーが Backward で求めた勾配の平均を計算し全ワーカーに配ります。Optimize のステップでは、この平均の勾配が利用されます。全ワーカーは学習開始後は常に同じパラメータを持ちます。

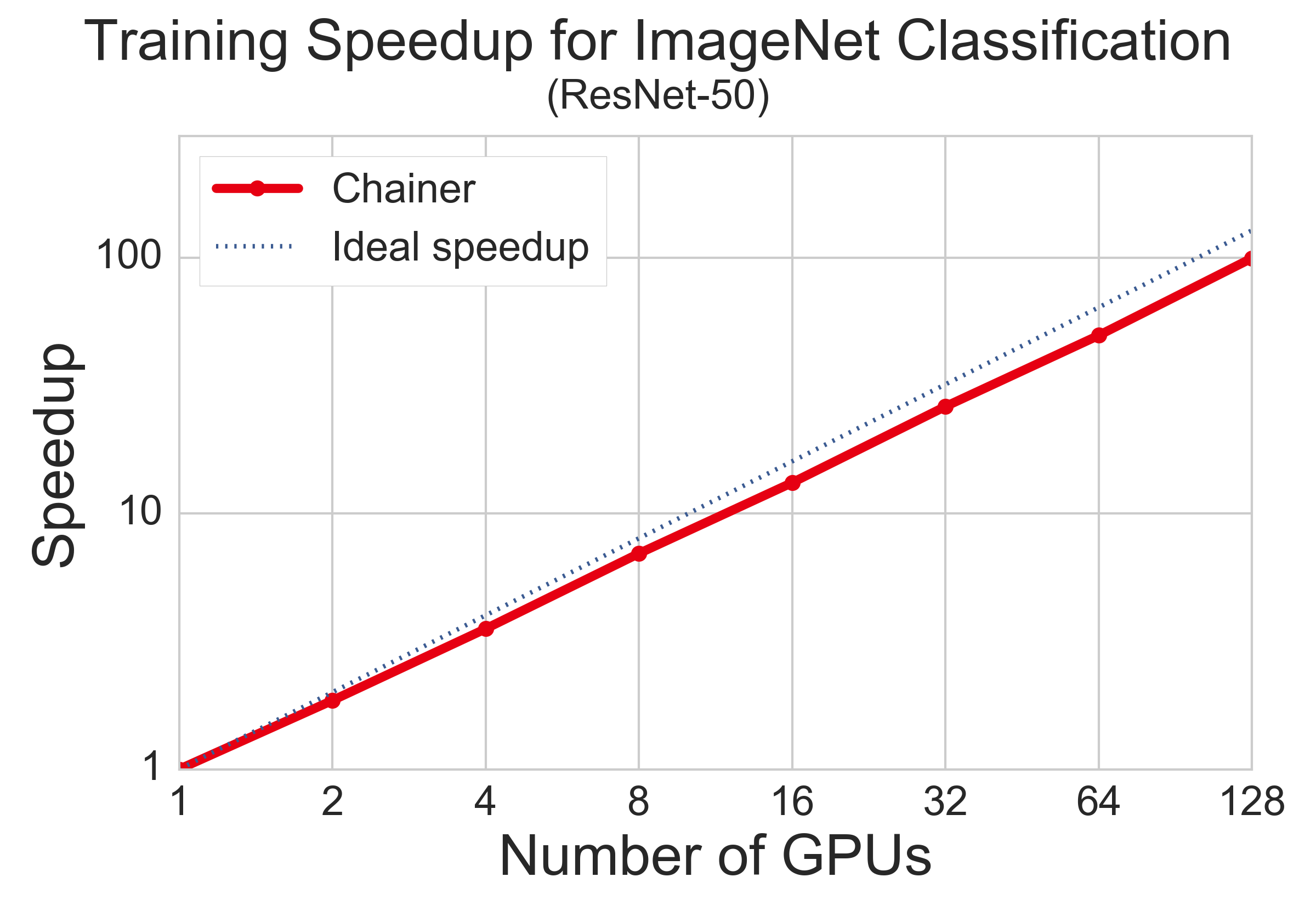
下図は以前に行った大規模ベンチマークの結果です。ChainerMN で 128 GPU を利用し画像分類の学習を約 100 倍高速化することができました。詳しくはこちらの記事をご覧ください。
利用方法の概要
以下、ChainerMN の利用方法の概要を紹介します。詳しくはドキュメントをご覧ください。
セットアップ
ChainerMN をインストールする前に、CUDA-Aware MPI, NVIDIA NCCL のセットアップが必要です。
CUDA-Aware MPI
ChainerMN は MPI を利用しており、MPI は CUDA-Aware 機能が利用できる必要があります。CUDA-Aware 機能をサポートするオープンソースの MPI には Open MPI, MVAPICH などがあります。以下は Open MPI を CUDA-Aware でインストールする例です。
./configure --with-cuda make -j4 sudo make install
複数ノードで利用する場合、InfiniBand 等の高速なインターコネクトの利用を推奨します。
NVIDIA NCCL
NCCL はノード内の GPU 間の集団通信を高速に行うためのライブラリです。こちらを参考にビルド・インストールし、環境変数を適切に設定して下さい。
ChainerMN
ChainerMN は pip よりインストールできます。
pip install chainermn
学習コードの変更
ChainerMN を利用した分散学習を行うためには、既存の Chainer による学習コードに変更を加える必要があります。ドキュメント内のチュートリアルでは順を追ってこの手順を説明しています。
以下では、そのうちの最も重要なステップである、コミュニケータの作成と、オプティマイザの置き換えについて説明します。
コミュニケータ
コミュニケータは以下のように作成します。
comm = chainermn.create_communicator()
通信はこのコミュニケータを通じて行います。コミュニケータからは、参加しているワーカー数や自分がその何台目か(rank と呼ばれます)などの情報を得ることができます。
オプティマイザ
ChainerMN は Chainer のオプティマイザを置き換えることによりワーカー間の通信処理を挿入します。以下は通常の Chainer のコードで Adam のオプティマイザを作成している部分です。
optimizer = chainer.optimizers.Adam()
ChainerMN では、以下のように create_multi_node_optimizer 関数を呼び出して、通信処理が追加されたオプティマイザを作成します。
optimizer = chainer.optimizers.Adam() optimizer = chainermn.create_multi_node_optimizer(optimizer, comm)
create_multi_node_optimizer によって作成されたオプティマイザは、通信処理が追加されている以外は通常のオプティマイザと同様に扱うことができます。
実行
mpiexec または mpirun コマンドを用いて学習スクリプトを起動します。以下は localhost 内で MNIST example を 4 プロセスで起動する例です。
mpiexec -n 4 python train_mnist.py
終わりに
以上、ChainerMN の利用法を駆け足で紹介しました。かなりの部分を省略しているので、実際に利用される際にはドキュメントを見て頂ければと思います。
ChainerMN は今後、通信と計算のオーバーラップ、ワーカー間の非同期な計算、勾配の圧縮による通信効率化、耐障害性などの課題に取り組み、改善を続けていく予定です。