Blog
この度、Chainerで開発したモデルをNVIDIAの推論エンジンTensorRTに変換しNVIDIA GPU上で高速に推論するための実験的ツールchainer-trtをOSSで公開しました。この記事ではその概要、開発の背景と位置づけを簡単に紹介したいと思います。
https://github.com/pfnet-research/chainer-trt.git
はじめまして。PFNエンジニアの鈴尾(すずお)です。いつも同じアバターを使っているので、社内や社外でお魚さんと呼んでいただけることもあります。
深層学習技術の急速な発展に伴って、いよいよエッジへの推論器のデプロイという形での実用化が進んできました。学習時の速度がモデル開発の効率に直結するように、推論時の速度は製品に載せるハードウェアのコストに直結するため、高速に推論できることは極めて重要です。ここで推論とは、ニューラルネット(NN)の順伝搬処理のみを実行し解釈可能な出力(例えば、物体検出の結果など)を得るプロセスを指します。Chainerは一般に非常に高速な深層学習フレームワークとして知られ、また学習に用いたコードをほとんどそのまま推論に用いることができます。しかしながら、特定の種類のデバイス上で、入力の大きさやアーキテクチャおよびパラメータが固定されたNNの順伝搬処理のみに注目した場合、最適化の余地はまだまだあります。
NVIDIAのTensorRTはこのような需要に対応するため開発された推論エンジンの一つです。
Deploying Deep Neural Networks with NVIDIA TensorRT
How to Speed Up Deep Learning Inference Using TensorRT | NVIDIA Developer Blog
TensorRTは完全に静的なNNと固定のデバイス(GPU)を前提とし、あらかじめ深さ方向ないしは幅方向に隣接する層を可能な限り統合するなどの計算グラフレベルの最適化、指定されたGPU上で最も実性能の良いCUDAカーネルを計測に基づいて自動選択するなどの実装レベルの最適化、計算グラフ中の破棄可能なメモリ領域を同定し再使用するなどのメモリレベルの最適化、および16bit浮動小数点数や8bit整数を用いた低精度計算へのpost-training変換などを施します。これをビルド段階と呼びます。
推論時は、このビルド段階で構築した実行計画に基づいて処理を行うだけであるため、NVIDIA GPU上で極めて高速に順伝搬処理を行うことができます。
これまでChainerで開発・学習したモデルをTensorRT推論器に変換する仕組みはONNXを介する方法しかありませんでした。この場合少々複雑なTensorRTのC++ APIを理解し、CPUおよびGPU上の生ポインタを責任持って管理するなどの作業が生じるため、これらを可能な限り吸収しかつChainerからTensorRT化をスムーズに行うことができないかを検証するべく、実験的ツールchainer-trtを開発しました。
一言でまとめるとchainer-trtは、TensorRTのC++ APIを用いてTensorRTにNNの構造とパラメータを教え最適化を走らせることによってChainerのモデルをTensorRT推論器に変換し、またそれを実行する、といった作業を行うための薄いラッパーです。
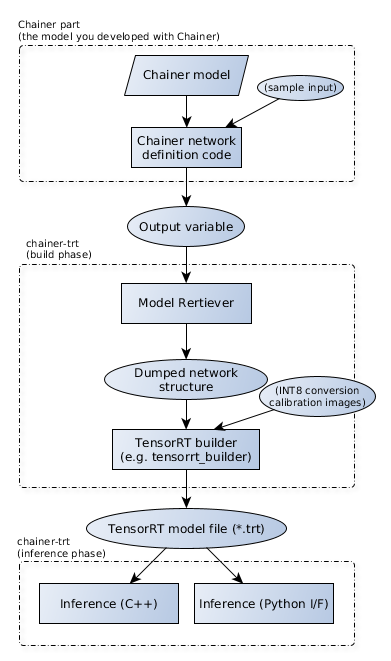
chainer-trtの仕組み
chainer-trtを使う上では、大きく3段階の作業が必要です。
1段階目は、PythonによってChainerの流儀で書かれた順伝搬コードをもとに、計算グラフをchainer-trt独自の中間形式に書き出すプロセスです。chainer-trtでは、これをModelRetrieverと呼ぶPythonパートが担当します。
計算グラフの全ての情報を得るのは、ちょうどChainerの機能の一つであるComputationalGraphと同じ仕組みで行われています。すなわち、順伝搬後に得られる出力Variable(chainer.VariableNode)から計算グラフを終端(入力側)まで順にたどっていく方法です。多くの場合、順伝搬のコードそのものに対するchainer-trt対応のための特別な変更は必要ありません。
中間形式の実体は1つのディレクトリであり、これは計算グラフの構造を表すmodel.jsonと各層の重みを表す*.weightsファイルを含みます。
下記のスニペットは、ImageNet学習済みのResNet50モデルを中間形式に書き出す処理です。見ての通り、通常の推論コードに少しchainer-trtの要素を外付けしているだけです。
import numpy as np
import chainer
import chainer_trt
# NNを用意
net = chainer.links.ResNet50Layers()
# ダミー入力を作成
x = chainer.Variable(np.random.random((1, 3, 224, 224)).astype(np.float32))
# ModelRetrieverを作成し、入力に名前をつける(任意)
retriever = chainer_trt.ModelRetriever("resnet50")
retriever.register_inputs(x, name="input")
# ダミー入力を用いて順伝搬を実行
with chainer.using_config('train', False):
with chainer_trt.RetainHook(): # おまじない
y = net(x)['prob']
# 計算グラフを取得し、全ての情報を保存する
retriever(y, name="prob")
retriever.save()
2段階目は、先程書き出した中間形式の情報を読み込みTensorRTのC++ APIを用いて推論器のビルドを走らせるプロセスで、chainer-trtのC++パートがこれを行います。推論を実行させたい対象デバイスの上でchainer-trtのビルド実行関数を呼ぶと、まもなくそのデバイス専用の推論器(実体は1つのファイル)ができあがります。
#include <chainer_trt/chainer_trt.hpp>
...
// ModelRetrieverの出力ディレクトリを指定し、推論エンジンを構築・保存する
auto m = chainer_trt::model::build_fp32("resnet50");
m->serialize("resnet50/fp32.trt");
上記のスニペットはユーザの書いたC++からこのビルド処理を行う例ですが、TensorRTの機能であるINT8量子化を行わない場合については標準でコンパイルされる小さなツールを下記のように呼ぶだけでも全く等価な推論器が構築できます。
(INT8量子化を伴う場合は、キャリブレーションと呼ばれるプロセスをNNごとに行う必要があるため、専用のビルドツールをユーザが実装する必要があります。)
% tensorrt_builder -i resnet50 -o resnet50/fp32.trt
3段階目は、その推論器を用いて推論を実行するプロセスで、chainer-trtのC++パートがこれを行います。ユーザはまず入力データと出力先バッファをCPU上ないしGPU上に用意し、それぞれがNNのどの入力・出力に対応するか(1つのNNは複数の入力や出力を持つことができ、これを名前で識別できます)などの情報とともにchainer-trtの推論実行関数を呼び出します。すると推論処理が走り、出力結果が返ってきます。
厳密にはビルドされた推論器のファイルはchainer-trtに依存するものではなく、chainer-trtを経由せず直接TensorRTのC++ APIを呼んで利用することができます。しかしながらchainer-trtは典型的なユースケースに関してメモリ管理や入出力の指定方法などを簡易化しCUDAの煩雑なコーディングをある程度隠蔽しているため、chainer-trtでビルドした推論器はchainer-trtで実行するのが便利でしょう。
#include <chainer_trt/chainer_trt.hpp>
...
// 構築した実行エンジンを読み込み、ランタイムを作成
auto m = chainer_trt::model::deserialize("renet50/fp32.trt");
chainer_trt::infer rt(m);
// CPU上の入力・出力バッファを用意し、入力バッファに入力データを読み込んでおく
std::vector<float> x(...);
std::vector<float> y(...);
load_input(x, ...);
rt.infer_from_cpu(1, {{"input"s, x.data}}, {{"prob"s, y.data}});
// 出力がyに入っている
同梱されているImageNetおよびYOLOv2のサンプルを用いた場合の1バッチ推論の平均実効時間、すなわち画像を入力して結果が得られるまでの推論レイテンシを測定してみました。
| モデル | Chainer FP32 (ms/img) | TensorRT FP32 (ms/img) | TensorRT INT8 (ms/img) |
| VGG16 | 4.713 | 2.259 | 1.384 |
| GoogLeNet | 13.809 | 0.974 | 0.624 |
| ResNet50 | 19.062 | 2.145 | 0.851 |
| YOLO v2 | 20.749 (12月14日訂正) | 6.151 | 4.579 |
環境: GeForce GTX 1080Ti, i7 7700K, CUDA 10, TensorRT 5.0, Ubuntu 18.04, Chainer 5.1.0, ChainerCV 0.11.0
GoogLeNetなどの細かな層が多数積み重なったようなNNでは演算量に対して計算グラフ構築のオーバヘッドが相対的に多くなるため、特にTensorRTの活用による高速化の恩恵を受けやすい傾向があります。ただしChainerベースの推論であっても、バッチ数を大きくし複数のCUDAストリームで推論を並列実行するなどの工夫によってスループットはかなりTensorRTベースの推論に近づけることができます。推論のレイテンシが特に重要な場合は、TensorRTで推論器を構成することがきわめて有効です。
コードに同梱しているREADMEドキュメントでは、導入方法(現在のところ、手動でのコンパイル作業が必要です)、より詳細な動作原理、並列化・バッチ化による高スループット化の方法、INT8量子化の使い方、numpy/cupy arrayから直接推論を走らせることのできるPythonインタフェースの使い方など詳細を解説しています。
社内での活用
社内ではいくつかのプロジェクトでchainer-trtを活用して推論を高速化しています。
最も典型的な活用例としては、実製品となる組み込み機器上での画像認識器の開発が挙げられます。計算能力上の制約が多い現場では、TensorRTの活用による高速化が必要不可欠でした。
面白いところでは、探索問題における評価関数を近似するNNを学習しこれをTensorRTで高速化することで全体の処理時間を大幅に短縮するという活用例がありました。別の例としては、強化学習のような問題設定において正確だが計算時間かかる物理シミュレータを同様にNNで近似後TensorRTで高速化することで学習全体を高速化するという例もあります。
Menohとの関係
次に、Menohとの関係についても述べておきたいと思います。
PFNでは、ONNXベースの推論ライブラリMenoh(R)を今年6月にリリースし、現在も活発に開発しています。MenohはONNXとして書き出したNNをもとに推論を行うライブラリで、主に以下のような極めて優れた特長を持っています。
- Python/C++に限らない豊富な言語バインディング
- ONNXを用いることで、Chainerのみに必ずしも依存しない汎用性
- プラガブルなバックエンド
特にバックエンドとして、もともとMenohはIntel製CPU上で深層学習のための演算を高速に実行するためのライブラリMKL-DNNを用いていましたが、現在TensorRTバックエンドを選択できるようにするべく開発を進めています。
これに対してchainer-trtは、
- ChainerのモデルをTensorRTに迅速に変換することのみを目的とする
- ONNXに依存しない
といった思想で設計されています。
2点目は特に重要で、ONNXに依存する選択をしている限りは現在のONNXで表現できないオペレータを含むようなNNは原理的に扱えないという困難があります(※1)。TensorRTの場合はプラグインという仕組みにより、TensorRTさえも標準サポートしていないような任意のオペレータをユーザが自らCUDA実装しNN内で使うことができますが、ONNXを中間形式とした場合この自由度がONNXの表現能力によって制約されてしまいます。chainer-trtはONNX非依存の独自中間形式をとるという選択をすることで、実装さえすれば提案されたばかりのオペレータなどを迅速に利用可能にできるような作りにしました(※2)。
※1: ONNXに任意の拡張を施せるようにする構想はいくつか検討されているそうですが、当面の間は使えるオペレータの種類に制約がある状態は続くと考えられます。
※2: もちろんこのように実装されたプラグインオペレータに関してはTensorRTによる自動的かつ高度な最適化の対象とはなりませんが、そのようなオペレータの存在のみによってNNのTensorRT化自体を諦める必要がなくなります。
これらのことから、ごく一般的なオペレータのみで構成されるほとんどのNNは、Menohによって十分にその超高速推論の恩恵に与れることと思います。ONNXで表現できないオペレータを使いたい、またそのオペレータの独自実装を自ら行うことができる方にはchainer-trtが役に立つでしょう。
歴史的には、実はchainer-trtはONNXが昨秋発表される前より社内で開発しています。したがってONNX非依存という選択をしたというよりは、そうするより他になかった当初の設計のまま今に至っていると言う方が正確な表現です。技術的には、Menohとchainer-trtは全く異なるコードベースから始まっており、情報交換をしつつ独立に開発が進んでいます。
Menohは今後も汎用的な推論ライブラリとして最新の高度な需要に追従するため大規模に開発が継続されていく見込みです。chainer-trtはChainerとTensorRTの間をとりもつ実験的プロジェクトとして、TensorRT本体の各種新機能への追従やカスタムオペレータの拡張などを中心に、またインタフェースやドキュメント改善なども含めた開発をしていく見込みです。
ぜひ実機での推論に課題を抱えている皆様のお役に立てればと考えております。また、皆様からのフィードバックをお待ちしています。
