Blog
こんにちは。Preferred Networksの自動運転チームです。
PFNは、2016年1月6日〜1月9日にアメリカのラスベガスで開催されたCES 2016でロボットの学習による自動走行のデモを行いました。これはPreferred Networksとトヨタ自動車様、NTT様との共同展示です。展示はトヨタ自動車様のブースの一部で行われました。
このブログではその中でどのような技術が使われているのかについて簡単に解説します。
背景
人工知能(強化学習)による自動走行は人工知能の黎明期よりとりくまれており,ロボットカーの自動走行などが60年代頃から試行されていました。
ルールベースやプログラムでも走行できますが、なぜ学習が必要なのでしょうか?
実際の交通環境、特に市街地の交通環境は非常に複雑であり、全てのパターンをあらかじめ列挙し、それに対する制御を漏れ無く書き表すのは困難です。一説には交差点のありうるパターンは千を超えるという話があります。
特に問題なのが、例外が大きな事故を引き起こしてしまう点です。例えば車線を逆走してきた車がいた場合や突然隣の車両がルールをやぶり車線を割り込んできた場合、またそれらの組み合わせが発生した場合に、それに正しく対応できなければ事故をひきおこします。それら全ての例外に対する対処法をあらかじめ用意しておくのは困難です。
また、新しいセンサや認識手法の登場により空間認識の精度は大幅に向上し、周辺の車や人をかなり正確に検出することが可能となっています。しかし大量に認識された結果を制御にどのように使うのかは難しくなっています。例えば交差点においては100を超える障害物(車、人、自転車など)が検出され、それらの位置や速度、向きといった情報が得られます。これらの情報を利用しての制御の複雑度は急速にあがります。
学習による制御はこれらの問題を解決します。学習の過程で経験から最適な運転技術を獲得します。また、センサ情報から制御を決めており、様々な種類のセンサ情報を組み合わせて最適な制御を実現できます。学習により獲得された運転技術は汎化されており、未知の状況にも対応できます。もし危ない場面があったとしても、次からは同じような間違いをおかすことはありません。経験を積めば積むほどより安全な運転を実現することができます。
一方で学習による制御が全てを解決するわけではありません。例えば強化学習により作られたモデルはブラックボックスでどのような挙動をとるのかがわかりません。作ったプログラムの安全性をどのように保障できるのか、既存の制御とどのように組み合わせられるのかが問題となります。そのため現時点では実際の自動車で使われているわけではありません。今後こうした課題を一つ一つ解決していく必要があります。学習の理論面の理解もこれから非常に重要になってきます。
今回のデモンストレーションでは、現時点での人工知能、強化学習ではどの程度のことまでできているのかを示したものであり、機械学習、特に深層学習の最新の研究成果を多く取り込んでいます。
今回のデモの手法
今回のデモで使用したロボットカーとステージは以下の様なものです。
- ロボットカーの大きさ
縦幅43cm, 横幅20cmの車両を利用しました。
写真のようにシルバーのプリウスのカバーを付けました。
- ロボットカーのモーター
左と右のタイヤにそれぞれモーターがついており、タイヤの回転の強弱を調整することで、車の速度と角速度を決めることができます。 - ロボットカーのARマーカー
各ロボットカーの屋根にはユニークなARマーカーが貼り付けられています。ステージの真上に設置されているカメラでこれを撮影し、サーバー上で動いているシミュレータと同期を取ります。なお,強化学習の入力には車の位置は与えません(現実の問題では使えません。また位置情報が使えると問題はとても簡単になります。)。このARマーカーによる位置情報はライダーのシミュレーション、報酬計算のみに利用されます。 - ステージ
アクリル板の壁に囲まれた3m x 3mの正方形のステージを利用しました。中央付近には4つの障害物(CES本番では直径10cmの円柱)を設置しました。交差点コースのデモでは各車は障害物の間を通り抜けるようなコースを与えられています。隣り合う障害物の間隔は約60cmのため、複数台の車が中央に集まった場合には、避けるための空きスペースはほとんどありません。
デモシステムは強化学習の一種であるDeep Q Learningをベースに作られています。詳しくは以前の松元の記事の解説をご参照ください。
https://research.preferred.jp/2015/06/distributed-deep-reinforcement-learning/
今回のデモでは、「前方向」「後方向」「右方向」「左方向」「左前方向」「左後方向」「右前方向」「右後方向」「ブレーキ」の9種類の行動を用意しました。車はセンサから得られた情報から各行動のQ値を比較し、どの行動を取るべきかを選択します。
前提として各車には走行コースが割り当てられており、主に以下の二つの指標をベースに賢い走行を学んでいきます。
- コースにそってなるべく速く移動する。
- 他の車両や壁、障害物にぶつからない。
理由は後述しますが、ニューラルネットの学習はすべてシミュレータ上で行い、その学習結果を実機で動かしました。学習時には以下の様な手順でニューラルネットを訓練していきます。
- センサ情報の計算
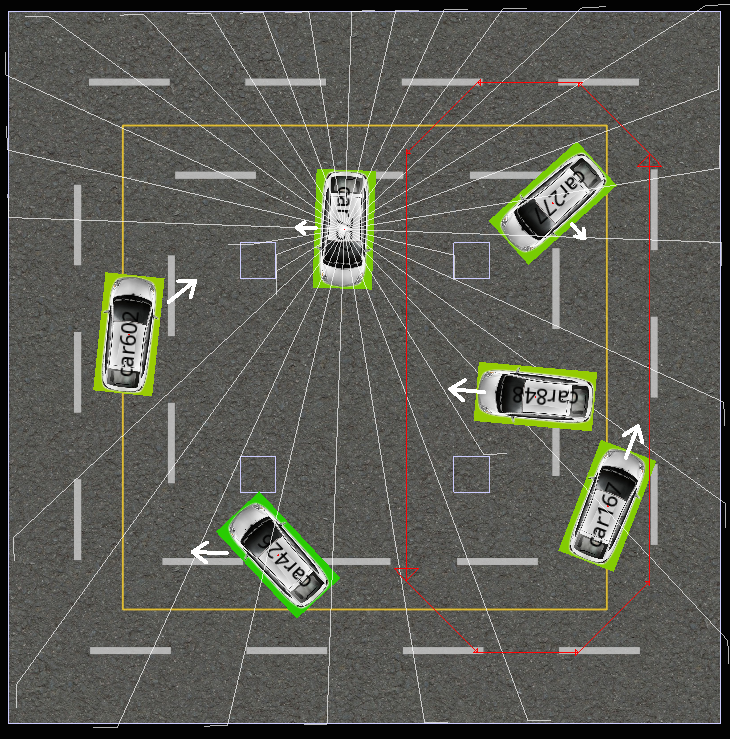
シミュレータ上で32方向のライダーから得られる情報を計算します。各ライダーは光線を発射し、光線が障害物や他のロボットカーにぶつかるとその距離と角度を得ることができます。以下のGUIのスクリーンショットで、車を中心に360度各方向に伸びている直線がシミュレーションされたライダーの光線です。このGUIでは1台しか表示していませんが、実際にはすべてのロボットカーのセンサ情報を計算しています。これらのセンサ情報はQ値を計算するニューラルネットの入力として使われます。このほかに自車のモーターの状態、過去の行動履歴も入力として使います。それ以外のexplicitな情報(自車や他車の位置や向きなど)は入力として使っていません。
- 行動の選択
確率1-εでQ値が最大となる行動、または確率εでランダムな行動を選択します。これはε-greedyと呼ばれる手法です。 - 車の移動
2.で選択された行動に従ってシミュレータ上の車を動かします。
- 選択された行動の評価
3.で車を移動させてそれが良い行動(例:コースにそってまっすぐ走っている)であったならばプラスの報酬、悪い行動(例:車や障害物と衝突してしまった)であればマイナスの報酬を与えます。そのときのセンサ情報、行動、報酬などをメモリーと呼ばれる場所に記録し、複数の車で共有します。メモリーには上限があり、古いものから順に捨てられます。 - ニューラルネットの学習
メモリーに記録されている情報からランダムに選び出し、その結果を用いてニューラルネットを訓練していきます。車の数が多ければ多いほど多種多様な情報がメモリーに蓄積されるため、学習が効率よく進みます。
実機環境で動かすデモシステムの流れは以下のようになります。ここでは予めシミュレータで学習済みのニューラルネットを利用します。
- ロボットカーの認識
車に取り付けられたARマーカーを天井に取り付けられたカメラで撮影し、実環境とシミュレータの同期を取ります。 - センサ情報の計算
シミュレータ上で各車両の32個のライダーから得られる情報を計算します。 - 最適な行動の選択
得られたセンサ情報を入力として与え、Q値が最大となる行動を最適な行動とみなして選択します。 - 実機に命令を送る
計算された最適な行動からモーターの変化量を決め、サーバーから通信モジュールを介して実際の車に命令を送り、モーターの値を調整します。
今回のデモは2015年6月のInterop用に松元が開発したものを作り直し、改良を加えたものです。車やコース以外での主な改良点は以下の様なものです。
- 強化学習
最近発表されたばかりの論文も含め、様々なアルゴリズムを試行錯誤しながら実験しました。また、学習時にカリキュラムを組むことで易しい問題から始め、徐々に難しい問題を学習させたり、学習が進むに従い報酬のパラメータを変更するなどの複雑なパラメータチューニングも試してみました。しかし、最終的にはアルゴリズムを改良することでカリキュラム学習や複雑なチューニングを行うことなく賢い走行を獲得できるようになりました。実装にはもちろんChainerを使いました。 - シミュレータ
ニューラルネットの学習には実機環境を使わずに全てシミュレータ上で行いました。実機での学習ではロボットカーが衝突した時の復帰に人手が必要で手間がかかってしまったり、カメラのFPSなどがボトルネックとなり学習に時間がかかってしまいます。これを実現するためには現実の実機環境とできるだけ同じ条件のシミュレータを実装することが重要です。また評価も人が目で動作を確認する方法だと人間がボトルネックとなってしまうため、良い学習の指標をスコア化して評価を自動化し、実験効率を上げる必要がありました。今回のデモではこれらの課題をクリアすることでシミュレータ上で効率良く様々な学習方法を試すことができました。 - カメラ認識
車の検出はARマーカーを用いて行われますが、CESの展示会場では様々な照明機器が使われており、可視光カメラを使って検出した場合に誤検出が多くなる可能性があります。今回はよりロバストな検出をするために、赤外線カメラを使って認識しています。カメラの付近に強い赤外線光を放つLEDライトを設置し、ARマーカーとして再帰性反射材を用いることで、検出対象のARマーカー以外のものがカメラにほぼ写り込まないようにできます。 - 通信
会場では様々な無線通信が飛び交っており、サーバーと車の間で安定して通信を行うことは通常は困難です。今回は、NTT様に特別な通信モジュールを用意していただくことで、この通信を安定して行うことができました。 - ストリーム処理基盤
今回のデモシステムのパイプラインを実現するために弊社で開発中のストリーム処理基盤を利用しました。こちらについては後日情報公開をする予定です。
これまでの強化学習による自動走行と異なる点
よく質問で「強化学習で昔から自動運転をやっていたので何が新しいの?」という話がありましたが、次の点で異なります。
- 車両の幅に対して道路が狭く、車が密集した交差点という難易度の高い問題を扱っています。また、学習時には存在しない、人が操作する車からの回避という困難な問題も扱っています。
unofficial demonstration: a red car is manually controlled by human. other cars try to avoid collisions #CES2016 pic.twitter.com/JCCyoBBygU
— 岡野原 大輔 (@hillbig) January 7, 2016
これまでに説明したように最初の段階では衝突だらけで全く走らず様々な技術を組み合わせることでシミュレーション上でも実機でも衝突は全く起きないレベルになりました。
- センサはライダー情報(32方向の距離と角度)を使っており、お互いの車両の位置や速度はわかっていません。また、センサや通信などはランダムに”わざと”一時的に落とし、実際の車で使えるようなシナリオを扱っています。
- Deep Q Learningと同様に、生の入力から直接制御を決めるように学習しています。そのため、違うセンサ、制御方式であっても特に工夫しなくても使うことができます。
- 学習結果は全ての車でリアルタイムで共有されており、学習を加速することができます。また、ある車でしか経験しなかったレアイベントの経験を共有することができます。
まとめ
今回のデモの中で,学習で獲得された走行技術は人間が良いと思っている走行とは異なる場合があることがわかりました。例えば,ロボットカーは周囲を全て同時に集中して見ることができるため、前方向と同じように後方向にも躊躇なく移動します。そのため,交差点では車両間隔をあけるために後ろがあいているなら少し後ろに下がります。
今回のデモは実際の車ではありませんでしたが、人間よりもリッチなセンサを載せた車で、できるだけ早くより安全な走行を実現できるように研究開発を加速させていきたいと思います。
また、今回のCESデモ出展に関して、トヨタ自動車様とNTT様をはじめ、様々な方々からのご協力を頂きました。この場を借りてお礼申し上げます。