Blog
私が2012年にニューラルネットの逆襲(当時のコメント)というのをブログに書いてからちょうど5年が経ちました。当時はまだDeep Learningという言葉が広まっておらず、AIという言葉を使うのが憚られるような時代でした。私達が、Preferred Networks(PFN)を立ち上げIoT、AIにフォーカスするのはそれから1年半後のことです。
この5年を振り返る良いタイミングだと思うので考えてみたいと思います。
1. Deep Learning Tsunami
多くの分野がこの5年間でDeep Learningの大きな影響を受け、分野特化の手法がDeep Learningベースの手法に置き換わることになりました。NLP(自然言語処理)の重鎮であるChris Manning教授もNLPで起きた現象を「Deep Learning Tsunami」[link] とよびその衝撃の大きさを表しています。
その適用範囲は最初想定されていた画像認識、音声認識分野だけにとどまらず、機械翻訳、生物情報処理、最適化、ロボティクスなど多岐にわたっていきました。
2. Deep Learning Frameworkの登場
2012年当時はDeep Learningの研究開発をしようと思った時、使える代表的なライブラリはTorchとTheanoしかありませんでした。その後、2013年末にYanqing Jiaが博士論文を書く過程で作ったCaffeが登場し、2015年6月には弊社PFNからChainerを発表、2015年9月にはGoogleからTensorFlowがリリースされます。その後も各会社がそれぞれのDeep Learning Frameworkを発表していきました。
Chainerは開発者の得居がGW明けに突然作ってきて、使ってみると簡単にかけるものだと驚いたのを覚えています。それまではC++やGoで書いていたのですが、その時とは雲泥の差でした。numpyをはじめとしたpythonの強力な数値計算/データ解析用ライブラリ群の力も合わせpythonによりDeep Learningの研究開発をする流れが急速に広まりました。
また、Chainerが最初に唱えたDefine-by-Runの考え方はコミュニティに受け入れられ、その後PyTorchやTensorFlow Eager execusionなどでも採用され影響を与えていきました。
今ではPythonで数十行から数百行コードを書くだけで、複雑なネットワークを持ったモデルを分散学習することができ、CPU、GPUどちらであっても気にせず、簡単に書くことができます。
3. 強化学習との融合
深層学習は強化学習と融合し、大きなブレークスルーをもたらしました。DQNによりAtari2600の様々なゲームが人間と同レベルでプレイできるように学習できることが大きな話題となりました。
元々強化学習は、教師あり学習とは違って、環境からのスカラー値の報酬のみで複雑な制御を獲得できる有望な手法でした。さらに深層学習により価値関数や方策(状態に応じてどの行動を選択するか)の表現力が大きく上がると、これまで困難と思われた問題を次々解けるようになりました。その中でもAlphaGo[オリジナル, AlphaGo Zero]がトップ棋士をやぶったことは大きなマイルストーンとなりました。
弊社もCES2016で強化学習を利用したロボットカーの自動運転のデモンストレーションなどでその可能性について世の中に示していきました[link]
強化学習は未だに学習、利用ともに様々な課題がありますが急速に研究が進んでおり今後ますます重要になるでしょう。最近の強化学習については、Deep RL Bootcampの資料などが参考になるでしょう。
4. 研究の爆発
DNNは最初は限られた研究グループのみが研究成果をあげていましたが、現在は世界中の企業、研究グループが次々と研究成果をあげるようになっています。どこの国や地域、企業でもいいアイディアさえあれば、すぐに大きなインパクトをあげられるようになっています。
これにはarxivなどのオープンジャーナルが大きな役割を果たしています。以下にarxivの関連カテゴリ(cs.AI,cs.LG,cs.CV,cs.CL,cs.NE,stat.ML)への投稿数のグラフをあげます[link より図を引用]
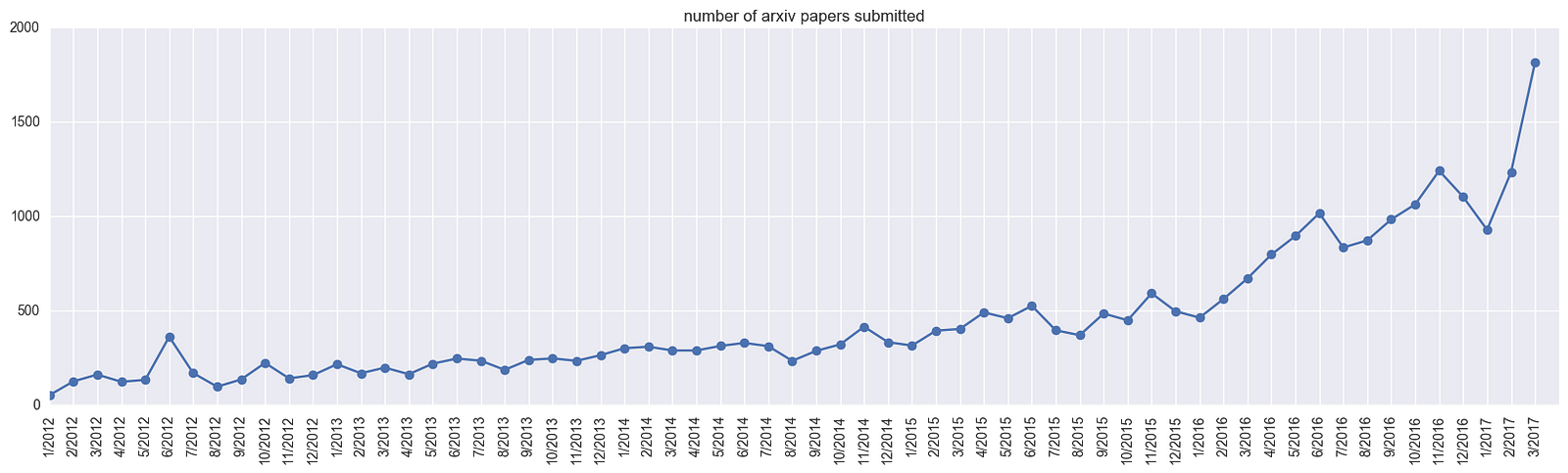
これまで研究は国際学会やジャーナル論文が中心でしたが、いつでも誰でも投稿できるオープンジャーナルが登場し、研究プロセスは非常に加速されました。発表された論文が数日後に別の論文で引用されることも珍しくありません。
また、論文と一緒に実験用コードをgithubなどで公開することで、さらに知識の共有が進むようになりました。
一方、オープンジャーナルでは査読がなく論文は玉石混交となり、質が下がるという危惧はあります。しかし注目された研究はすぐに世界中で追試がされチェックされ、怪しいところがあるとRedditなどで指摘されたりします。また、今後はコメントツール(例:Librarian)などを標準が使うことが普及すればさらに論文の信頼性を担保できるようになるかもしれません。
また、大量の論文が投稿され全部追うことは難しくなり、論文キュレーションツールとして、話題になっている論文をまとめるarxiv sanity preserverやdeeplearn.orgなども登場しています。
私も読んだ論文の中から面白そうなものはをツイートしていますが、それでも重要な論文を見逃すことがよくあるほど、研究成果が爆発的に出てきています。
5. 生成モデル
Deep Learningは、生成モデルでも大きなブレークスルーを起こしました。
例えば、VAE(変分自己符号化器)は連続変数を潜在変数とした場合でも誤差逆伝搬法だけで効率的に学習できるものであり衝撃的でした。
そして二つのニューラルネットワークを競合させて学習するGAN(敵対的生成モデル)がこれまでの生成モデルではできなかった高精細な画像を生成できることは非常に大きなインパクトを与えました。
GANは学習が難しいため、登場から1年間は殆ど後続の研究がなかった中、DCGANが自然な画像生成モデルの学習に成功し、実写と変わらないレベルの画像を生成できることを示しました[最近のGANの生成例,イラストの生成例] 。一方で、GANはその学習の難しさからダイエット本や英語本と同じように多くの研究を生み出しています(GAN Zoo)。
その後、通常の確率モデルの最尤推定による学習では,現実世界のデータにみられるサポート(確率密度値が0ではない)が低次元であるような分布を学習することができず[link]、GAN(の変種)が実現するOptimal Transport (最適輸送)やIntegral Probability Metricsを使わなければいけないということがわかり、Implicit Probabilistic Modelという名とともにGANが注目されました。
6. 理論解明
Deep Learningがなぜ学習できるのか、なぜモデルが大きいのに汎化性能が高いのか、何を学習できて何はできないのかといった問題に多くの研究者が取り組んできました。
もともとDeep Learningは非線形のモデルであり,パラメータ数が非常に大きく、従来の統計モデルや機械学習理論からは、謎に包まれていました。
完全な解明には至ってはいないものの分かってきたのは、Deep Learningの確率的勾配降下法(SGD)は極小解にはまりにくいだけでなく[link1 link2]、汎化性能が高いような幅が広い解を見つけられるということ[link]、またミニバッチ正規化[link]、スキップ接続[link]といったテクニックが学習を容易にし、適切なノイズを与えることで汎化性能をあげていることがわかってきています。
また、従来の機械学習の考え方ではパラメータ数が少ない方がモデルの複雑さは下がり、過学習しにくくなりますがDNNの場合、汎化性能はモデルが大きければ大きいほど高いことも予想されています[link]。
7. Software 2.0
またDeep Learningが工学的にも、「推論時と計算量と使用メモリ量が固定で済む」「モデルサイズを変えることで計算量と精度のトレードオフをスムーズにできる」「GPUのような並列処理向けプロセッサの開発が非常に容易になる」という利点があることも注目されてきました。
これをAndrej KarpathyはSoftware2.0と名付け、Deep Learningが単なる機械学習のツールではなく、ソフトウェアの作り方を変える大きなパラダイム・シフトを起こすと述べています。
今後について
それでは今後はどのようになっていくのでしょうか。未来の予測は難しく、5年前に予想した時は、Deep Learningがここまで広く適用されるということは予想できていませんでした。それでもしてみましょう。
1. 多数の教師なし学習の登場
現在、ディープラーニングが大きく成功しているのは正解ラベルがついたデータを使った教師あり学習です。一方、本当に難しい問題を解くには教師なし学習が重要になると考えられます。
Yann LeCunは講演の中で「知能をケーキに例えるなら、教師なし学習は本体であり、教師あり学習はケーキの飾り、強化学習はケーキ上のサクランボぐらいである。私達はケーキの飾りやサクランボの作り方はわかってきたがケーキ本体の作り方はわかっていない」
と述べています。
また、Geoffrey Hinton教授も[link]「脳のシナプスは10^14個あるが,人は10^9秒しか生きられない。サンプル数よりパラメータ数の方がずっと多いことになる。(これらのシナプスの重みを決定するためには)1秒あたり10^5個の制約が必要となり,多くの教師無し学習をしているとの考えに行き着く」と述べています。
世の中の膨大なデータの大部分は教師データがついていません。これらのデータを活かせる学習手法が望まれています。教師なし学習の中でも”pretext task”は、関係のなさそうなタスクを学習することで、その副作用として本当に学習したいことを学習することが増えています。現時点でも、様々なpretext taskが提案されています。おそらくpretext taskは一つだけではなく無数あり、それらを組み合わせて強力な学習を実現していると思われます[例, 表1に例多数]。しかし、これまで多くの教師なし学習手法が提案されているものの、それを使って教師あり学習、強化学習の性能を大きく向上する決定的な手法はまだ見つけられていません。
また、大きく成功するには学習データ数やモデルの大きさのスケールが数桁足りないという可能性があります。
人は1年間に10時間/日*3600秒/時*365日*10Hz=1.3億回の画像をみてそれらで予測学習や、補間学習、ノイズ除去学習をすることができます。
ただでさえ教師あり学習は人よりもサンプルを必要としているので教師なし学習でも大きな成果を生み出すには莫大な量のサンプルが必要になるかもしれません。
2. 微分不可能な要素を含んだNN
現在のディープラーニングは微分可能な構成要素を組み合わせて作られています。これにより誤差逆伝播法が可能となり、どれだけネットワークが複雑になっても、出力を修正するには各モジュールをどれだけ修正すればよいかが正確にかつスケーラブルに求めることができます。
一方で、微分不可能な構成要素も困難な問題を解くためには不可欠です。例えば、汎化するロジックやルールを獲得するためには、過学習につながる情報の中で不要な情報を捨てることが必要になります。これには複数の値を一つの値に縮約(contraction)する、または離散化するということが必要になります。
あの猫もこの猫もそのまま扱わずに「猫」という離散値を割り振ってその上でルールを学習すれば、誤った入力との相関を見つけることはありません。
一方、離散化は微分不可能な計算ですので、誤差逆伝播が使えません。しかし、この場合でも勾配の不偏推定量を求められる手法がいくつか登場しています[例 Relax]。
また、強化学習においても”環境”は微分不可能でそもそもどのような計算がされるのかはわかりませんが、これも同様に環境のダイナミクスをシミュレーションするNNを作り、伝播することができるでしょう。これは環境を想像する能力やデータから獲得した上でのモデルベース学習とも関係します。
離散変数によるゲートはconditional computationやmixture of expertシステムのように使うモジュールをダイナミックに選択し、そのモジュールだけ計算させることで計算量を劇的にさげることができます。
今後は、誤差逆伝播法だけではなく、離散変数での最適化も可能な離散/組み合わせ最適化法[link]、遺伝的アルゴリズムや、進化戦略[link], を使った手法も必要になるでしょう。
3. メタ学習、継続学習
より複雑な問題を解くために、ある学習問題に他の学習結果を利用することが必要となります。今のようにある問題に対して特定の学習器で学習させるのではなく複数の問題、タスクを同時にまたは順番に一つの学習器を学習させることが重要となってきます。
一つの人工知能システムが非常に多くの問題を解けるようになる汎用人工知能システムに到達するにはまだ多くの問題を解く必要があり難しいですが、それでも関連するタスクを一緒に、または次々と学習していくことで一つの学習に必要なサンプル数を大幅に削減できたり、性能を大きくあげるといったことは可能になると考えられます。
カリキュラム学習、ブートストラップ学習といった、複数の学習を計画をたてて学んでいくことも今後大きく伸びていくことと考えられます。
4. シミュレーションとの融合、説明可能性
現実世界の問題を解く上で、現実世界の様々な制約を克服するためにシミュレーション上で学習、検証することがより一層必要になります。その上、どのように計画を立てているのかを説明する上でもブラックボックスであるニューラルネットワークモデルの中の計算処理を説明するのではなく、実際に実現例を示し、シミュレーション上でこうなっているからと説明することが増えていくと考えられます。
今の生成モデルは、様々な条件付けをして生成をすることで滅多にとれないデータを生成し、その上で学習、検証することを可能にします。これは、システムに想像力を備えさせた上で、まだ経験していない環境で学習できることを可能とさせるでしょう。
5. 人や既存システムとの協調
これらAIシステムが実問題に適用されていく中で、いかに人と協調するか、既存システムと協調するかが重要となってきます。全ての問題を完璧に解くことが理想ですが、そうならなかった場合でも、解けている問題だけを担当させ、残りを人や既存システムが担当することが多くなるでしょう。
その場合、認識結果や理由をわかりやすくするだけでなく、制御できるようにチューナーのようなツマミが必要になるかもしれません。また、人が自分の感覚を拡張したと感じられるように、操作可能性や応答性が重要になります。人馬一体という言葉がありますが、そのように人がAIシステムを自由自在に扱うことができるようになることが必要となるでしょう。